TAO Pretrained Sparse4D with ResNet-101 Backbone
TAO Sparse4D Model Card
Model Overview
Description:
TAO Sparse4D is an advanced three-dimensional (3D) multi-camera detection and tracking network. It generates precise 3D bounding boxes and tracking IDs for a diverse set of objects across multiple camera views. The model was developed by NVIDIA as a part of the TAO model family. The provided model is pre-trained on the Multi-Target Multi-Camera (MTMC) Tracking 2025 subset from the NVIDIA PhysicalAI-SmartSpaces dataset also utilized for the 2025 AI City Challenge. This model is ready for commercial use.
The model in this card was trained & evaluated on the following warehouse-centric classes: Person, Fourier_GR1_T2_Humanoid, Agility_Digit_Humanoid, Nova_Carter, Transporter and Forklift.
License/Terms of Use:
GOVERNING TERMS: Use of this model is governed by the NVIDIA Open Model License.
Deployment Geography:
Global
Use Case:
TAO Sparse4D is designed for 3D multi-camera object detection and tracking in indoor environments like warehouses and logistics facilities. The model detects & tracks objects across multiple camera views for applications including warehouse automation, safety and workflow optimization in industrial settings, providing spatial understanding of a scene.
Release Date:
v1.0 Model - NGC - 06/13/2025
v1.1 Model - NGC - 11/30/2025
v2.0 Model - NGC - 01/23/2026 via NGC
v2.1 Model - NGC - 02/27/2026 via NGC
v2.2 Model (ResNet50) - NGC - 05/12/2026 via NGC
v2.2 Model (ResNet101) - NGC - 05/12/2026 via NGC
References
- Wang, Y., Pusegaonkar, S., Wang, Y., Li, A., Kumar, V., Sethi, C., ... & Biswas, S. (2026). A Unified 3D Object Perception Framework for Real-Time Outside-In Multi-Camera Systems. arXiv preprint arXiv:2601.10819.
- Lin, X., Pei, Z., Lin, T., Huang, L., & Su, Z. (2023). Sparse4d v3: Advancing end-to-end 3d detection and tracking. arXiv preprint arXiv:2311.11722.
Model Architecture
Architecture Type: Convolution Neural Network (CNN) based backbone with Transformer based decoder layers.
Network Architecture: ResNet101 backbone with Transformer based decoder layers.
Number of model parameters: 7.8 × 10⁷ parameters
This work leverages the Sparse4D v3 model & is tailored for indoor environments like warehouses with static camera setups. Sparse4D is a query based technique which involves sampling sparse features for better computational efficiency compared to other dense 3D detection & tracking based techniques. The architecture features a ResNet101 backbone and processes time-synchronized frames from multiple cameras. Key components include the backbone, a Feature Pyramid Network (FPN), and multiple decoder layers incorporating Multi-Scale Deformable Aggregation blocks (featuring key-point generation, feature sampling, visibility net module & embedding generation) along with refinement & classification layers. The model is trained on regression, classification & ID losses. The model also consists of an Instance Bank module utilized for tracking ID assignment & management. Along with the 3D bounding box information & object ID, Sparse4D also outputs an instance feature containing high-dimensional semantics from the image encoder. The training algorithm optimizes the network to minimize the classification loss, regression loss & ID loss.
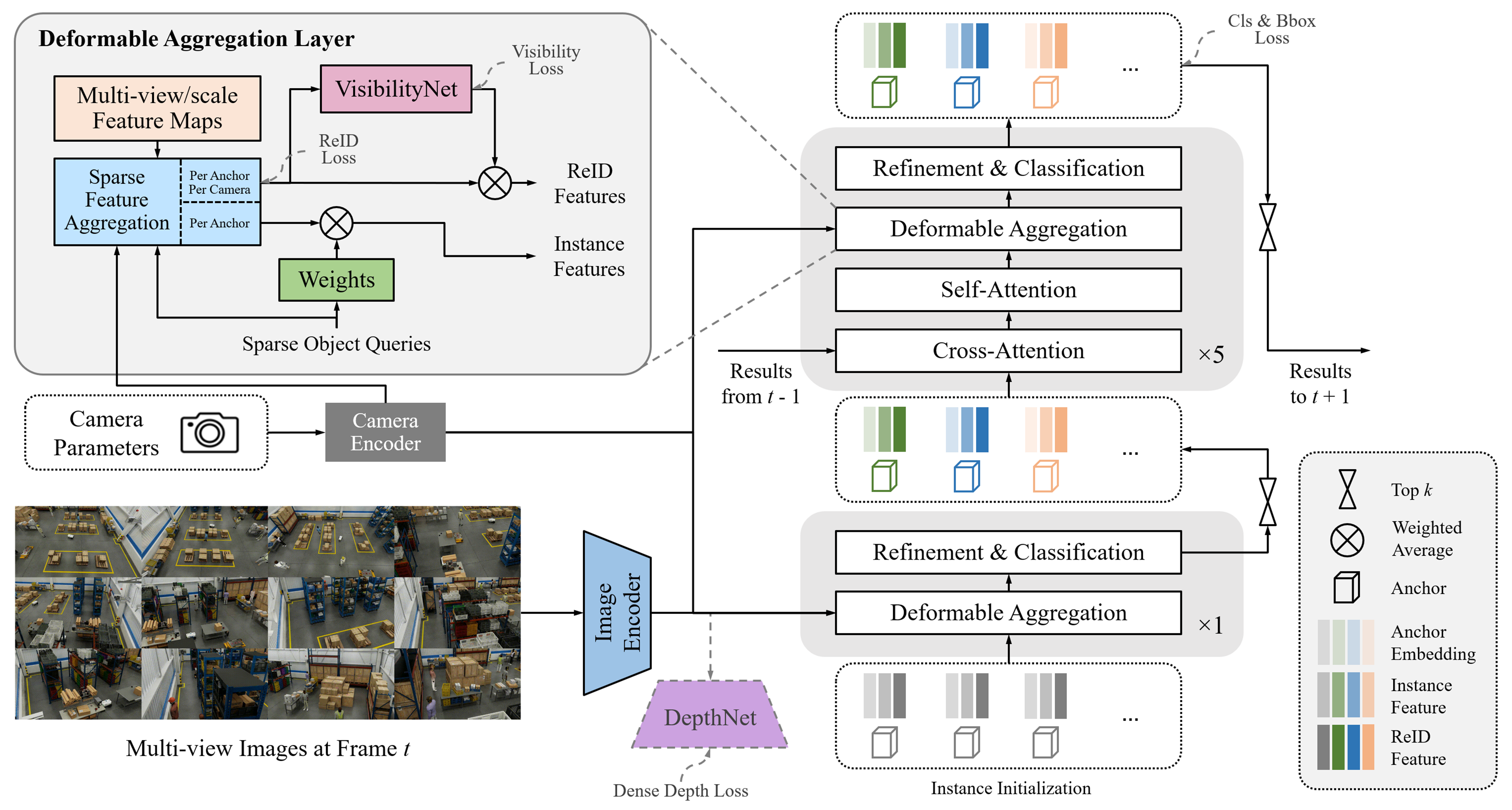
Input:
Sparse4D is trained on RGB images, camera calibration files, ground truth 3D bounding boxes & object ids, and optional depth maps. Since performing 3D multi-camera detection and tracking across large regions like warehouses with high-density camera setups is computationally expensive, we partition large regions into overlapping groups called Bird's Eye View (BEV) group. Each BEV group contains multiple cameras and serves as the fundamental training unit for Sparse4D.
Input Type(s): Each BEV group will have cameras with RGB images, Camera calibration file, Ground Truth with 3D bounding boxes & Optional Depth Maps available via HuggingFace or generated synthetically by Nvidia Isaac Sim Replicator.
Input Format: Red, Green, Blue (RGB) images stored in raw png/jpg/hdf5 and Depth Maps stored in png/hdf5. Can support input resolution of 3 x 1080 x 1920 for both RGB & Depth Maps. Data preprocessing is required for grouping images & depth maps from multiple cameras to appropriate BEV groups. This can be done via the TAO Data Service.
Input Parameters: Multiple dimensions. See below for detailed model input shapes.
Other Properties Related to Input: 3 x 1080 x 1920 (C x H x W) resolution images for both RGB & Depth Maps. Data Pre-Processing needed via TAO Data Services. No alpha channel required.
Note that depth maps are optional and not required for evaluation or inference. The raw model inputs are as follows:
| Dimension | Description |
|---|---|
B | Batch size |
C | Number of channels |
N | Number of cameras |
H | Image height |
W | Image width |
Q | Number of queries |
M | Number of output boxes |
E | Number of instance features |
| Input Name | Type | Shape | ResNet101 Shape | Description |
|---|---|---|---|---|
img | List[Tensor] | (B, N, C, H, W) | (1, N, 3, 540, 960) | Input image tensor |
projection_mat | List[Tensor] | (B, N, 4, 4) | (1, 10, 4, 4) | List of projection matrices |
image_wh | List[Tensor] | (B, N, 2) | (1, 10, 2) | List of image width and height |
input_cached_feature | List[Tensor] | (B, 600, 256) | (1, 600, 256) | List of cached features |
input_cached_anchor | List[Tensor] | (B, 600, 11) | (1, 600, 11) | List of cached anchor |
prev_exists | List[Tensor] | (B) | (1) | Indicates if previous frame exists or not |
interval_mask | List[Tensor] | (Bx1x1) | (1x1x1) | Boolean to describe the interval mask |
- No. of cameras is dynamic in the model.
- Model is initialized with zero tensors for the
input_cached_feature,input_cached_anchor,prev_exists&interval_maskat the first frame. These tensors will be updated automatically via instance bank from the second frame & onwards.

Output:
Output Type(s): Tensors consisting of bounding boxes in 3D , object confidence scores, classes, class confidence scores, tracking object ID & instance features.
Output Format: List of Tensors.
Output Parameters: Multiple dimensions. See below for detailed model output shapes.
Other Properties Related to Output: Please see the details below.
The final output is a list with length of batch size after post-processing. Each element is a dictionary with the following keys:
| Output Name | Type | Shape | ResNet Shape | Description |
|---|---|---|---|---|
boxes_3d | List[Tensor] | (B, M, 10) | (1, 600, 10) | List of 3D boxes: (x, y, z, width, length, height, yaw, velocity_x, velocity_y, velocity_z) in OV coordinates |
scores_3d | List[Tensor] | (B, M) | (1, 600) | List of object confidence scores (classification scores * centerness score) |
labels_3d | List[Tensor] | (B, M) | (1, 600) | List of class labels |
cls_scores | List[Tensor] | (B, M) | (1, 600) | List of classification scores |
instance_ids | List[Tensor] | (B, M) | (1, 600) | List of instance IDs |
instance_feats | List[Tensor] | (B, M, E) | (1, 600, 256) | List of instance features |
where:
- x, y, z - 3D coordinates of the bounding-box centroid in the world coordinate system which is in meters.
- width, length, height - Box dimensions in meters along its x (width), y (length) and z (height) axes of the object-centered coordinate system, with the origin at the centroid.
- yaw - Euler angle in radians about the y-axis of the object-centered coordinate system defining the box’s heading in the world coordinate system. (Pitch and roll are assumed zero.)
- velocity - 3D velocity vector components in meters per second (m/s) in the world coordinate system, representing the object's instantaneous motion along the x, y, and z axes respectively.
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
Software Integration:
Runtime Engine(s):
- DeepStream - 7.1
- TAO - 6.1.0
Supported Hardware Microarchitecture Compatibility:
- NVIDIA Blackwell
- NVIDIA Hopper
- NVIDIA Lovelace
- NVIDIA Ampere
Preferred/Supported Operating Systems:
- Linux
These models are designed for use with NVIDIA hardware and software. For hardware, the models are compatible with any NVIDIA DataCenter GPU. For software, the models are specifically designed for the TAO Toolkit.
Model versions (Latest):
- trainable_v2.2 (ResNet50 / ResNet101) - Pre-trained model for Sparse4D.
- deployable_v2.2 (ResNet50 / ResNet101) - Model for Sparse4D deployable to DeepStream or TensorRT.
Training, Testing, and Evaluation Datasets
Dataset Overview
** Total Size:
| Subset | No. of scenes | No. BEV groups | No. of objects per scene | No. of cameras per scene | Duration of each camera sequence | FPS |
|---|---|---|---|---|---|---|
| Train | 90 | 3469 | 1-120 | 1-20 | 5 mins | 30 FPS |
** Total Number of Datasets: 3 Datasets in total including (MTMC Tracking 2025 and COSMOS augmented version of the MTMC Tracking 2025 dataset, SCOUT dataset)
** Dataset partition: Training 80%, Testing 10%, Validation 10%
** Time period for training data collection: Collected throughout the year 2024-2025.
** Time period for testing data collection Collected throughout the year 2024-2025.
** Time period for validation data collection Collected throughout the year 2024-2025.
The model is trained on the MTMC Tracking 2025 dataset available on HuggingFace.
Data Format & Preprocessing
Raw Data (MTMC Tracking 2025/AI City Challenge Format)
This raw data includes .mp4 RGB video files, depth maps stored in HDF5 format, ground_truth.json, calibration.json & map.png. For more details on these files including the ground truth format please refer to the raw dataset format here.
The raw data may also be obtained from Nvidia Isaac Sim Replicator Agent IRA. When collected via this route, RGB image data & depth maps can be in frame output/HDF5 output. Utilize the TAO Data Service to convert your raw data format (AICity) to pickle format (OVPKL) accordingly.
Pickle File Structure (OVPKL format)
The above raw data format needs to be converted to a pickle files for model training via the TAO DataService. The model will utilize these pickle files along with the above files for training. An example command can be found in the sparse4d finetuning notebook. The pickle file will consist of the items.
The process generates pickle files (.pkl) containing scene information. Each pickle file is a dictionary with the following top-level keys:
metadata: (dict) Contains metadata about the dataset.infos: (list) A list of dictionaries, where each dictionary contains information about a specific frame in the scene.
metadata key
The metadata dictionary contains the following keys:
| Key | Type | Description | Example Value |
|---|---|---|---|
version | str | Version of the dataset or split. | 'trainval_split' |
split_type | str | Type of data split (e.g., 'all', 'train', 'validation'). | 'all' |
infos key
The infos key holds a list of dictionaries. Each dictionary in this list corresponds to a frame and contains the following keys:
| Key | Type | Description | Example Value (Illustrative) |
|---|---|---|---|
frame_idx | int | Index of the frame. | 0 |
cams | dict | Dictionary containing data for each camera in the frame. Keys are camera names (e.g., 'Camera', 'Camera_01'). | See cams Structure below. |
scene_name | str | Name of the scene. | 'Warehouse_014+bev-sensor-training-1' |
timestamp | float | Timestamp of the frame. | 0.0 |
token | str | Unique token for the frame. | 'Warehouse_014+bev-sensor-training-1__000000000' |
group_name | str | Name of the group this frame belongs to. | 'bev-sensor-training-1' |
instance_inds | np.ndarray | Array of instance indices present in the frame. | array([372, 171, 172, 631, 663]) |
asset_inds | np.ndarray | Array of asset indices corresponding to instances. | array([ 771, 772, 775, 2094, 1372]) |
gt_boxes | np.ndarray | Ground truth bounding boxes for objects in the frame. Shape: (N, 7) where N is the number of objects. Each row is [x, y, z, dx, dy, dz, heading]. | array([[-0.686, 1.073, ..., -0. ], ...]) |
gt_names | np.ndarray | Array of ground truth names for objects. | array(['agility_digit', 'gr1_t2', ...], dtype='<U18') |
gt_velocity | np.ndarray | Ground truth velocity for objects. Shape: (N, 3) for [vx, vy, vz]. | array([[0., 0., 0.], ...]) |
valid_flag | np.ndarray | Boolean array indicating if the ground truth data for each object is valid. | array([ True, True, ...]) |
gt_visibility | list | List of dictionaries, one for each ground truth object, indicating its visibility percentage in each camera. | [{'Camera': 1.0, 'Camera_01': 1.0, ...}, ...] |
cams Structure
The cams dictionary (within each element of the infos list) contains nested dictionaries, where each key is a camera identifier (e.g., 'Camera', 'Camera_01', etc.). Each of these camera-specific dictionaries has the following structure:
| Key | Type | Description | Example Value (Illustrative) |
|---|---|---|---|
data_path | tuple | Tuple containing paths to camera data. (h5_file_path, rgb_image_relative_path) | ('data/mtmc/Warehouse_014/Camera.h5', 'rgb/rgb_00000.jpg') |
depth_map_path | tuple | Tuple containing paths to depth map data. (h5_file_path, depth_image_relative_path) | ('data/mtmc/Warehouse_014/Camera.h5', 'distance_to_image_plane_png/distance_to_image_plane_00000.png') |
sample_data_token | str | Unique token for the sample data from this camera. | 'Warehouse_014+bev-sensor-training-1__000000000+Camera' |
cam_intrinsic | np.ndarray | 3x3 camera intrinsic matrix. | array([[916.249, 0., 960.], [0., 916.249, 540.], [0., 0., 1.]]) |
sensor2world_transform | np.ndarray | 4x4 transformation matrix from sensor coordinates to world coordinates. | array([[0.018, -0.999, ..., -4.731], ..., [0., 0., 0., 1.]]) |
3D bounding box information is transformed from OV coordinates to BEV coordiantes for faster convergence during training. During inference, results are converted back to OV world coordinates.
Public Datasets
MTMC Tracking 2025 Subset from NVIDIA PhysicalAI-SmartSpaces dataset
Private Datasets
NVIDIA COSMOS-augmented version of the MTMC Tracking 2025 dataset was used for training to improve data diversity and robustness across varying scenarios.
Self-Sourced Synthetic Data
- Overall Size per Modality: 80% of the overall data used for training was synthetic data collected from NVIDIA Isaac Sim Replicator.
- A description of the methods used to synthetically generate training data: Various warehouse related assets were imported in a scene with virtual cameras recording image data.
Training Data
The dataset statistics used for pretraining the model are as follows:
-
Data Modality - Image
-
Image Training Data Size - 1 Million to 1 Billion Images
-
Data Collection Method by dataset - Synthetic
-
Labeling Method by dataset - Synthetic
Properties (Quantity, Dataset Descriptions, Sensor(s)):
Please see above.
- Model was trained on the following moving object classes:
Person,Fourier_GR1_T2_Humanoid,Agility_Digit_Humanoid,Nova_Carter,TransporterandForklift. - Both validation & testing was conduction on random scenes from the MTMC Tracking 2025 subset.
Testing and Evaluation Datasets
Both validation & testing was conduction on random scenes from the MTMC Tracking 2025 subset.
-
Data Collection Method by dataset - Synthetic
-
Labeling Method by dataset - Synthetic
Properties (Quantity, Dataset Descriptions, Sensor(s)): We utilize a random scenes from the test set of the MTMC Tracking 2025 subset.
Methodology and KPI
The key performance indicator is Higher Order Tracking Accuracy (HOTA) per-class and the average HOTA obtained across all classes. We utilize the HOTA evaluation methodology to assess multi-object tracking accuracy.
Higher Order Tracking Accuracy (HOTA) is a metric that balances detection accuracy and association accuracy into a single unified score. It decomposes tracking performance into Detection Accuracy (DetA), which measures how well objects are localized, and Association Accuracy (AssA), which measures how well detections are linked over time into consistent tracks. HOTA is computed as the geometric mean of DetA and AssA, averaged over a range of localization thresholds. This provides a balanced, holistic measure of tracking quality that captures both spatial accuracy and temporal consistency.
The following scores are for v2.2 models trained on MTMC Tracking 2025 subset. The evaluation set and training set is disjoint.
ResNet50 backbone (v2.2)
| Object Class | HOTA | DetA | AssA | LocA |
|---|---|---|---|---|
Person | 53.93 | 59.13 | 49.54 | 73.34 |
Fourier_GR1_T2_Humanoid | 59.31 | 59.87 | 58.84 | 73.46 |
Agility_Digit_Humanoid | 52.69 | 52.57 | 53.50 | 70.72 |
Nova_Carter | 58.26 | 56.89 | 59.92 | 71.05 |
Transporter | 33.70 | 38.98 | 31.49 | 68.41 |
Forklift | 48.05 | 43.84 | 54.97 | 66.69 |
| Average | 50.99 | 51.88 | 51.37 | 70.61 |
ResNet101 backbone (v2.2)
| Object Class | HOTA | DetA | AssA | LocA |
|---|---|---|---|---|
Person | 57.96 | 58.99 | 57.11 | 73.29 |
Fourier_GR1_T2_Humanoid | 60.93 | 60.97 | 60.98 | 74.00 |
Agility_Digit_Humanoid | 54.00 | 53.32 | 55.32 | 71.02 |
Nova_Carter | 54.85 | 57.60 | 53.28 | 70.92 |
Transporter | 33.98 | 38.13 | 32.58 | 67.33 |
Forklift | 48.05 | 43.78 | 55.20 | 66.45 |
| Average | 51.63 | 52.13 | 52.41 | 70.50 |
Real-time Inference Performance
Inference runs through the DeepStream pipeline on TensorRT with mixed precision (FP16+FP32). The TensorRT columns capture model-only latency, while the DeepStream columns add the instance-bank pre- and post-processing overhead. The table summarizes how many cameras each GPU supports at 30, 15, and 10 FPS for the v2.0 model. Numbers in bold are measured (all TensorRT values and certain DeepStream values). DeepStream values not in bold are estimates based on the guidance that the DS microservice adds approximately 30% overhead over Sparse4D TensorRT model performance.
| GPU | TensorRT @30 FPS | DeepStream @30 FPS | TensorRT @15 FPS | DeepStream @15 FPS | TensorRT @10 FPS | DeepStream @10 FPS |
|---|---|---|---|---|---|---|
| 1 x A100-SXM4-80GB | 13 | 9 | 28 | 19 | 43 | 30 |
| 1 x B200 | 75 | 52 | 155 | 108 | 200 | 140 |
| 1 x GB200 | 101 | 70 | 200 | 140 | 200 | 140 |
| 1 x H100 NVL - 94GB | 23 | 16 | 48 | 33 | 72 | 50 |
| 1 x H100 SXM HBM3 - 80GB | 28 | 19 | 58 | 40 | 89 | 62 |
| 1 x H200 | 32 | 22 | 67 | 46 | 103 | 72 |
| 1 x L4 - 24GB | 3 | 2 | 6 | 4 | 9 | 6 |
| 1 x L40 | 8 | 5 | 16 | 11 | 26 | 18 |
| 1 x L40S - 48GB | 9 | 6 | 20 | 14 | 30 | 21 |
| 1 x RTX 6000 ADA | 9 | 6 | 19 | 13 | 27 | 18 |
| 1 x RTX PRO 6000 Blackwell (Server) | 28 | 19 | 58 | 40 | 89 | 62 |
| 1 x RTX PRO 6000 Blackwell (Workstation) | 29 | 20 | 59 | 41 | 90 | 63 |
| 1 x IGX Thor - T7000 iGPU (no dGPU) | 5 | 3 | 11 | 7 | 17 | 11 |
| 1 x IGX Thor - T7000 dGPU - RTX PRO 6000 Blackwell Max-Q Workstation Edition | 21 | 14 | 30 | 21 | 30 | 21 |
| 1 x AGX Thor - T5000 | 4 | 2 | 8 | 5 | 14 | 9 |
| 1 x DGX Spark | 5 | 3 | 11 | 7 | 17 | 11 |
Changelog
v2.2
- Released two backbone variants of the same recipe: ResNet50 (lower latency / smaller footprint) and ResNet101 (high accuracy), shipped under
sparse4d_rn50andsparse4d_rn101NGC model cards respectively. - The ResNet50 variant is built on top of an RT-DETR R50 pre-training initialization for stronger image features at half the backbone cost.
- Added
pallet_truckto the trained class set (person,gr1_t2,agility_digit,nova_carter,transporter,forklift,pallet_truck). - Expanded the training corpus to all available MTMC Tracking 2025 scenes (lazy-loaded), 3K+ BEV groups, and refreshed COSMOS-augmented data; mixed FPS training is unchanged.
- Refreshed kmeans anchor priors per backbone (
_ov_kmeans900_v2.2_r50.npy,_ov_kmeans900_v2.2_r101.npy).
v2.1
- Trained on a significantly expanded dataset: more synthetic environments (retail, hospital, supermarket), GTC'24 warehouse data, COSMOS-transferred data with BEV groups, and real-world SCOUT data.
- Leverages the upgraded camera grouping algorithm (SDU v1.2).
- Corrected forklift orientation annotations.
v2.0
- Increased the number of BEV groups to 1337 to improve accuracy across all benchmarks.
- Added COSMOS-augmented datasets to the training set, using an 80:20 split between synthetic data and COSMOS augmentations.
- Introduced multiple FPS settings in training to better handle low-frame-rate streams (1, 2, 3, 5, 6, 10, 15, and 30 FPS).
- Increased the regression weight for rotation loss to improve bounding box fitting accuracy.
v1.1
- Updated input image resolution to 960×540 and introduced camera embeddings to lift maximum camera limits.
- Expanded training set to 34 scenes spanning 500+ cameras and 380 BEV groups (1–18 cameras each).
- Supported classes:
Person,Fourier_GR1_T2_Humanoid,Agility_Digit_Humanoid,Nova_Carter,Transporter,Forklift. - Mixed input frame rates (10, 15, 30 FPS) to improve robustness to lower streaming FPS.
- Enabled sparser camera grouping with random frame dropping to mirror Data Service frame-loss scenarios.
- Fixed rotation bug in object annotations and retrained the model with corrected labels.
- New MSDA FP16 Kernel which helps improve throughput by ~1.5x-2x for Data Center GPUs available in the DeepStream Pipeline inside the Nvidia Video Search and Summarization (VSS) - Warehouse Blueprint release.
v1.0
- First commercial warehouse-focused 3D detection and tracking release.
- Input image resolution: 1408×512 and cameras limited to 20.
- Supported classes:
Person,Fourier_GR1_T2_Humanoid,Agility_Digit_Humanoid,Nova_Carter.
How to use this model
In order to use the model as pre-trained weights for transfer learning, please use the snippet below as a template for the model component of the experiment spec file to train a Sparse4D. For more information on experiment spec file, please refer to the Train Adapt Optimize (TAO) Toolkit User Guide.
model:
type: "sparse4d"
use_grid_mask: true
use_deformable_func: true
use_temporal_align: true
input_shape: [960, 540]
embed_dims: 256
neck:
type: "FPN"
num_outs: 4
start_level: 0
out_channels: 256
in_channels: [256, 512, 1024, 2048]
add_extra_convs: "on_output"
relu_before_extra_convs: true
depth_branch:
type: "dense_depth"
embed_dims: "${model.embed_dims}"
num_depth_layers: 3
loss_weight: 0.2
head:
type: "sparse4d"
num_output: 300
cls_threshold_to_reg: 0.05
decouple_attn: true
return_feature: true
use_reid_sampling: false
embed_dims: "${model.embed_dims}"
num_groups: 8
num_decoder: 6
num_single_frame_decoder: 1
drop_out: 0.1
temporal: true
with_quality_estimation: true
instance_bank:
num_anchor: 900
anchor: ???
num_temp_instances: 600
confidence_decay: 0.8
feat_grad: false
default_time_interval: 0.033333
embed_dims: "${model.embed_dims}"
use_temporal_align: "${model.use_temporal_align}"
anchor_encoder:
type: 'SparseBox3DEncoder'
vel_dims: 3
embed_dims: [128, 32, 32, 64]
mode: 'cat'
output_fc: false
in_loops: 1
out_loops: 4
operation_order: [
"deformable", "ffn", "norm", "refine", "temp_gnn", "gnn", "norm",
"deformable", "ffn", "norm", "refine", "temp_gnn", "gnn", "norm",
"deformable", "ffn", "norm", "refine", "temp_gnn", "gnn", "norm",
"deformable", "ffn", "norm", "refine", "temp_gnn", "gnn", "norm",
"deformable", "ffn", "norm", "refine", "temp_gnn", "gnn", "norm",
"deformable", "ffn", "norm", "refine"
]
temp_graph_model:
type: "MultiheadAttention"
embed_dims: 512
num_heads: 8
batch_first: true
dropout: 0.1
graph_model:
type: "MultiheadAttention"
embed_dims: "${model.head.temp_graph_model.embed_dims}"
num_heads: "${model.head.temp_graph_model.num_heads}"
batch_first: true
dropout: "${model.head.temp_graph_model.dropout}"
norm_layer:
type: "LN"
normalized_shape: "${model.embed_dims}"
ffn:
type: "AsymmetricFFN"
in_channels: 512
pre_norm:
type: "LN"
embed_dims: 256
feedforward_channels: 1024
num_fcs: 2
ffn_drop: 0.1
act_cfg:
type: "ReLU"
inplace: true
deformable_model:
embed_dims: "${model.embed_dims}"
num_groups: 8
num_levels: 4
attn_drop: 0.15
use_deformable_func: true
use_camera_embed: true
residual_mode: "cat"
kps_generator:
embed_dims: "${model.embed_dims}"
num_learnable_pts: 6
fix_scale:
- [0, 0, 0]
- [0.45, 0, 0]
- [-0.45, 0, 0]
- [0, 0.45, 0]
- [0, -0.45, 0]
- [0, 0, 0.45]
- [0, 0, -0.45]
refine_layer:
type: "SparseBox3DRefinementModule"
embed_dims: "${model.embed_dims}"
refine_yaw: true
with_quality_estimation: true
sampler:
num_dn_groups: 5
num_temp_dn_groups: 3
dn_noise_scale: [2.0, 2.0, 2.0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]
max_dn_gt: 128
add_neg_dn: true
cls_weight: 2.0
box_weight: 0.25
reg_weights: [2.0, 2.0, 2.0, 0.5, 0.5, 0.5, 0.0, 0.0, 0.0, 0.0, 0.0]
use_temporal_align: "${model.use_temporal_align}"
visibility_net:
type: "visibility_net"
embedding_dim: 256
hidden_channels: 32
loss:
reg:
type: "sparse_box_3d"
box_weight: 0.25
cls_allow_reverse: [5, 6, 7]
cls:
type: "focal"
use_sigmoid: true
gamma: 2.0
alpha: 0.25
loss_weight: 2.0
id:
type: "cross_entropy_label_smooth"
num_ids: "${dataset.num_ids}"
bnneck:
type: "bnneck"
feat_dim: 256
num_ids: "${dataset.num_ids}"
decoder:
type: "SparseBox3DDecoder"
score_threshold: 0.05
reg_weights: [2.0, 2.0, 2.0, 1 ,1, 1, 1, 1, 1, 1, 1]
Inference & Deployment:
For deployment of this model, please refer to the our Nvidia Video Search and Summarization (VSS) - Warehouse Blueprint release documentation.
Acceleration Engine: Tensor(RT)
Test Hardware:
- NVIDIA Datacenter GPUs
Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please make sure you have proper rights and permissions for all input image and video content; if image or video includes people, personal health information, or intellectual property, the image or video generated will not blur or maintain proportions of image subjects included.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Sub-cards.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns here.