1 class object detection network to detect faces in an image.
FaceDetect-IR Model Card
Model Overview
The model described in this card detects one or more faces in the given image / video. Compared to the PeopleNet model, this model gives better results detecting large faces, such as faces in webcam images.
Model Architecture
The model is based on NVIDIA DetectNet_v2 detector with ResNet18 as a feature extractor. This architecture, also known as GridBox object detection, uses bounding-box regression on a uniform grid on the input image. Gridbox system divides an input image into a grid which predicts four normalized bounding-box parameters (xc, yc, w, h) and confidence value per output class.
The raw normalized bounding-box and confidence detections needs to be post-processed by a clustering algorithm such as DBSCAN or NMS to produce final bounding-box coordinates and category labels.
Training
This model was trained using the DetectNet_v2 entrypoint in TAO. The training algorithm optimizes the network to minimize the localization and confidence loss for the objects. The training is carried out in two phases. In the first phase, the network is trained with regularization to facilitate pruning. Following the first phase, we prune the network removing channels whose kernel norms are below the pruning threshold. In the second phase the pruned network is retrained. Regularization is not included during the second phase.
Training Data
FaceDetectIR v1.0 model was trained on a proprietary dataset with more than 846K faces. The training dataset consists of images taken from cameras mounted at varied heights and angles, cameras of varied field-of view (FOV) and occlusions. While most training images are IR (gray) images, some color (RGB) images are added as seeded content to improve accuracy of the models.
Training Data Ground-truth Labeling Guidelines
The training dataset is created by labeling ground-truth bounding-boxes and categories by human labellers. Following guidelines were used while labelling the training data for NVIDIA FaceDetectIR model.
FaceDetectIR project labelling guidelines
- Face bounding boxes should be as tight as possible.
- Label each face bounding box with an occlusion level ranging from 0 to 9. 0 means the face is fully visible and 9 means the face is 90% or more occluded. For training, only faces with occlusion level 0-5 are considered.
- The datasets consist of webcam images so truncation is rarely seen. If faces are at the edge of the frame with visibility less than 60% due to truncation, this image is dropped from the dataset.
Performance
Evaluation Data
The inference performance of FaceIR v1.0 model was measured against 16559 proprietary images across a variety of environments, occlusion conditions, camera heights and camera angles.
Methodology and KPI
The true positives, false positives, false negatives are calculated using intersection-over-union (IOU) criterion greater than 0.5. The KPI for the evaluation data are reported in the table below. Model is evaluated based on precision, recall and accuracy.
The key performance indicators (KPI) are calculated for IR images only. There are no color images in our evaluation set.
| Model | FaceDetectIR | ||
|---|---|---|---|
| Content | Precision (in %) | Recall (in %) | Accuracy (in %) |
| Evaluation set | 99.8 | 96.40 | 96.21 |
Real-time Inference Performance
The inference is run on the provided pruned model at INT8 precision. The inference performance is run using trtexec on Jetson Nano, AGX Xavier, Xavier NX and NVIDIA T4 GPU. On the Jetson Nano FP16 inference is run. The Jetson devices are running at Max-N configuration for maximum GPU frequency. The performance shown here is the inference only performance. The end-to-end performance with streaming video data might slightly vary depending on other bottlenecks in the hardware and software.
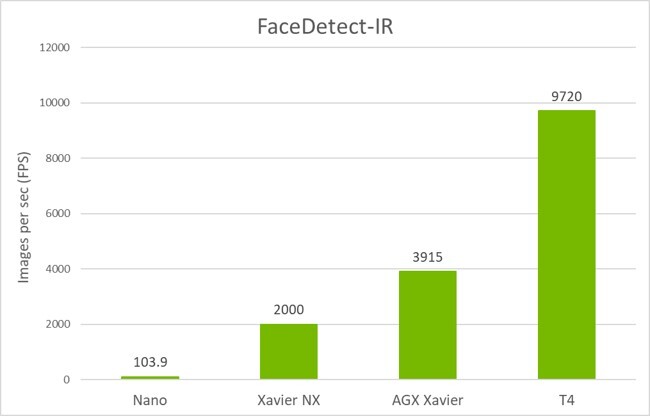
How to use this model
This model needs to be used with NVIDIA Hardware and Software. For Hardware, the model can run on any NVIDIA GPU including NVIDIA Jetson devices. This model can only be used with Train Adapt Optimize (TAO) Toolkit, DeepStream SDK or TensorRT.
The primary use case for this model is to detect faces from an IR (infrared) camera. The model can be used to detect faces from photos and videos by using appropriate video or image decoding and pre-processing. As a secondary use case the model can also be used to detect faces in RGB (color) images. However, this is not the main intended use for this model.
There are two flavors of the model:
- unpruned
- pruned
The unpruned model is intended for training using TAO Toolkit and the user's own dataset. This can provide high fidelity models that are adapted to the use case. The Jupyter notebook available as a part of TAO container can be used to re-train.
The pruned model is intended for efficient deployment on the edge using DeepStream SDK or TensorRT. This model accepts 384x240x3 dimension input tensors and outputs 24x15x4 bbox coordinate tensor and 24x15x1 class confidence tensor. DeepStream provides a toolkit to create efficient video analytic pipelines to capture, decode, and pre-process the data before running inference. DeepStream will then post-process the output bbox coordinate tensor and class confidence tensors with NMS or DBScan clustering algorithm to create appropriate bounding boxes. The sample application and config file to run this model are provided in DeepStream SDK.
The unpruned and pruned models are encrypted and will only operate with the following key:
- Model load key:
tlt_encode
Please make sure to use this as the key for all TAO commands that require a model load key.
Input
Gray Image whose values in RGB channels are the same. 384 X 240 X 3 (W x H x C) Channel Ordering of the Input: NCHW, where N = Batch Size, C = number of channels (3), H = Height of images (240), W = Width of the images (384) Input scale: 1/255.0 Mean subtraction: None
Output
Category labels (faces) and bounding-box coordinates for each detected face in the input image.
Instructions to use unpruned model with TAO
In order, to use this model as a pretrained weights for transfer learning, please use the below mentioned snippet as template for the model_config component of the experiment spec file to train a DetectNet_v2 model. For more information on the experiment spec file, please refer to the TAO Toolkit User Guide.
model_config {
num_layers: 18
pretrained_model_file: "/path/to/the/model.tlt"
use_batch_norm: true
objective_set {
bbox {
scale: 35.0
offset: 0.5
}
cov {
}
}
training_precision {
backend_floatx: FLOAT32
}
arch: "resnet"
all_projections: true
}
Instructions to deploy this model with DeepStream
To create the entire end-to-end video analytics application, deploy this model with DeepStream SDK. DeepStream SDK is a streaming analytics toolkit to accelerate deployment of AI-based video analytics applications. The pruned model included here can be integrated directly into deepstream by following the instructions mentioned below.
-
Run the default
deepstream-appincluded in the DeepStream docker, by simply executing the commands below.## Download Model: mkdir -p $HOME/facedetectir && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/facedetectir/versions/pruned_v1.0/files/resnet18_facedetectir_pruned.etlt \ -O $HOME/facedetectir/resnet18_facedetectir_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/facedetectir/versions/pruned_v1.0/files/facedetectir_int8.txt \ -O $HOME/facedetectir/facedetectir_int8.txt ## Run Application xhost + sudo docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:/opt/nvidia/deepstream/deepstream-5.1/samples/models/tlt_pretrained_models \ -w /opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models nvcr.io/nvidia/deepstream:5.1-21.02-samples \ deepstream-app -c deepstream_app_source1_labels_faceirnet.txt -
Install deepstream on your local host and run the deepstream-app.
To deploy this model with DeepStream 5.1, please follow the instructions below:
Download and install DeepStream SDK. The installation instructions for DeepStream are provided in DeepStream development guide. The config files for the purpose-built models are located in:
/opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models/opt/nvidia/deepstreamis the default DeepStream installation directory. This path will be different if you are installing in a different directory.You will need 2 config files and 1 label file. These files are provided in the
tlt_pretrained_modelsdirectory.deepstream_app_source1_faceirnet.txt - Main config file for DeepStream app config_infer_primary_faceirnet.txt - File to configure inference settings labels_faceirnet.txt - Label file with 1 classKey Parameters in
config_infer_primary_faceirnet.txttlt-model-key tlt-encoded-model labelfile-path int8-calib-file input-dims num-detected-classesRun
deepstream-app:deepstream-app -c deepstream_app_source1_faceirnet.txtDocumentation to deploy with DeepStream is provided in "Deploying to DeepStream" chapter of TAO User Guide.
Limitations
Small faces
NVIDIA FaceIR model does not give good results on detecting small faces (generally, if the face occupies less than 10% of the image area, the face is small)
Model versions
- unpruned_v1.0 - ResNet18 based pre-trained model.
- pruned_v1.0 - ResNet18 deployment models. Contains common INT8 calibration cache for GPU and DLA.
References
Citations
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR. (2016) Erhan, D., Szegedy, C., Toshev, A., Anguelov, D.: Scalable object detection using deep neural networks, In: CVPR. (2014) He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recognition. In: CVPR (2015)
Using TAO Pre-trained Models
- Get TAO Container
- Get other Purpose-built models from NGC model registry:
Technical blogs
- Train like a ‘pro’ without being an AI expert using TAO AutoML
- Create Custom AI models using NVIDIA TAO Toolkit with Azure Machine Learning
- Developing and Deploying AI-powered Robots with NVIDIA Isaac Sim and NVIDIA TAO
- Learn endless ways to adapt and supercharge your AI workflows with TAO - Whitepaper
- Customize Action Recognition with TAO and deploy with DeepStream
- Read the 2 part blog on training and optimizing 2D body pose estimation model with TAO - Part 1 | Part 2
- Learn how to train real-time License plate detection and recognition app with TAO and DeepStream.
- Model accuracy is extremely important, learn how you can achieve state of the art accuracy for classification and object detection models using TAO
Suggested reading
- More information on about TAO Toolkit and pre-trained models can be found at the NVIDIA Developer Zone
- TAO documentation
- Read the TAO getting Started guide and release notes.
- If you have any questions or feedback, please refer to the discussions on TAO Toolkit Developer Forums
- Deploy your models for video analytics application using DeepStream. Learn more about DeepStream SDK
- Deploy your models in Riva for ConvAI use case.
License
License to use these models is covered by the Model EULA. By downloading the unpruned or pruned version of the model, you accept the terms and conditions of these licenses.
Ethical Considerations
NVIDIA FaceIR model detects faces. However, no additional information such as race, gender, and skin type about the faces is inferred.
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.