A pre-trained model for automated detection of metastases in whole-slide histopathology images.
Model Overview
A pre-trained model for automated detection of metastases in whole-slide histopathology images.
The model is trained based on ResNet18 [1] with the last fully connected layer replaced by a 1x1 convolution layer.
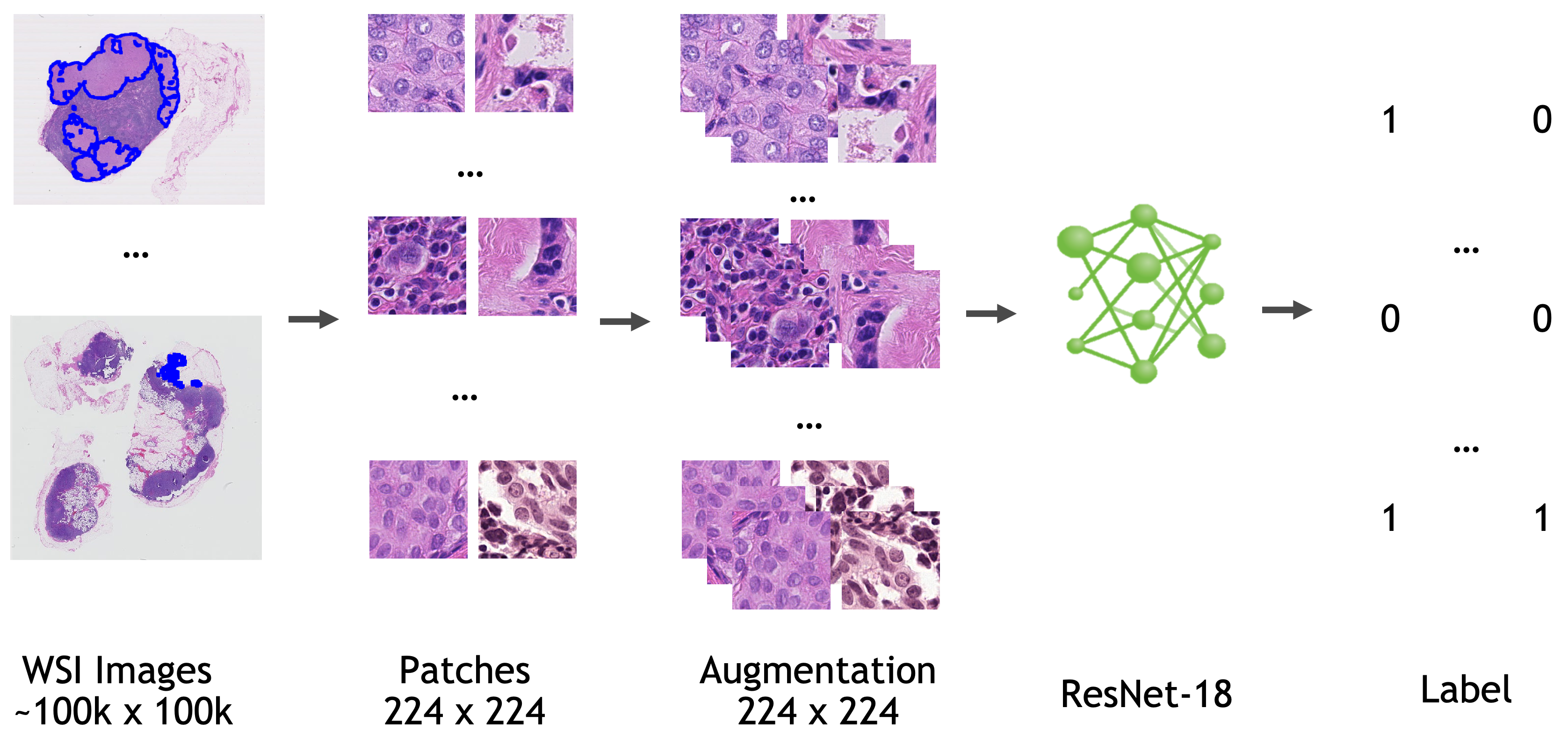
Data
All the data used to train, validate, and test this model is from Camelyon-16 Challenge. You can download all the images for "CAMELYON16" data set from various sources listed here.
Location information for training/validation patches (the location on the whole slide image where patches are extracted) are adopted from NCRF/coords.
Annotation information are adopted from NCRF/jsons.
- Target: Tumor
- Task: Detection
- Modality: Histopathology
- Size: 270 WSIs for training/validation, 48 WSIs for testing
Preprocessing
This bundle expects the training/validation data (whole slide images) reside in a {dataset_dir}/training/images. By default dataset_dir is pointing to /workspace/data/medical/pathology/ You can modify dataset_dir in the bundle config files to point to a different directory.
To reduce the computation burden during the inference, patches are extracted only where there is tissue and ignoring the background according to a tissue mask. Please also create a directory for prediction output. By default output_dir is set to eval folder under the bundle root.
Please refer to "Annotation" section of Camelyon challenge to prepare ground truth images, which are needed for FROC computation. By default, this data set is expected to be at /workspace/data/medical/pathology/ground_truths. But it can be modified in evaluate_froc.sh.
Training configuration
The training was performed with the following:
- Config file: train.config
- GPU: at least 16 GB of GPU memory.
- Actual Model Input: 224 x 224 x 3
- AMP: True
- Optimizer: Novograd
- Learning Rate: 1e-3
- Loss: BCEWithLogitsLoss
- Whole slide image reader: cuCIM (if running on Windows or Mac, please install
OpenSlideon your system and changewsi_readerto "OpenSlide")
Pretrained Weights
By setting the "pretrained" parameter of TorchVisionFCModel in the config file to true, ImageNet pre-trained weights will be used for training. Please note that these weights are for non-commercial use. Each user is responsible for checking the content of the models/datasets and the applicable licenses and determining if suitable for the intended use. In order to use other pretrained weights, you can use CheckpointLoader in train handlers section as the first handler:
{
"_target_": "CheckpointLoader",
"load_path": "$@bundle_root + '/pretrained_resnet18.pth'",
"strict": false,
"load_dict": {
"model_new": "@network"
}
}
Input
The training pipeline is a json file (dataset.json) which includes path to each WSI, the location and the label information for each training patch.
Output
A probability number of the input patch being tumor or normal.
Memory Consumption Warning
If you face memory issues in traning, you can lower the batch_size in the configurations to reduce the System RAM requirements.
Inference on a WSI
Inference is performed on WSI in a sliding window manner with specified stride. A foreground mask is needed to specify the region where the inference will be performed on, given that background region which contains no tissue at all can occupy a significant portion of a WSI. Output of the inference pipeline is a probability map of size 1/stride of original WSI size.
Note on determinism
By default this bundle use a deterministic approach to make the results reproducible. However, it comes at a cost of performance loss. Thus if you do not care about reproducibility, you can have a performance gain by replacing "$monai.utils.set_determinism" line with "$setattr(torch.backends.cudnn, 'benchmark', True)" in initialize section of training configuration (configs/train.json and configs/multi_gpu_train.json for single GPU and multi-GPU training respectively).
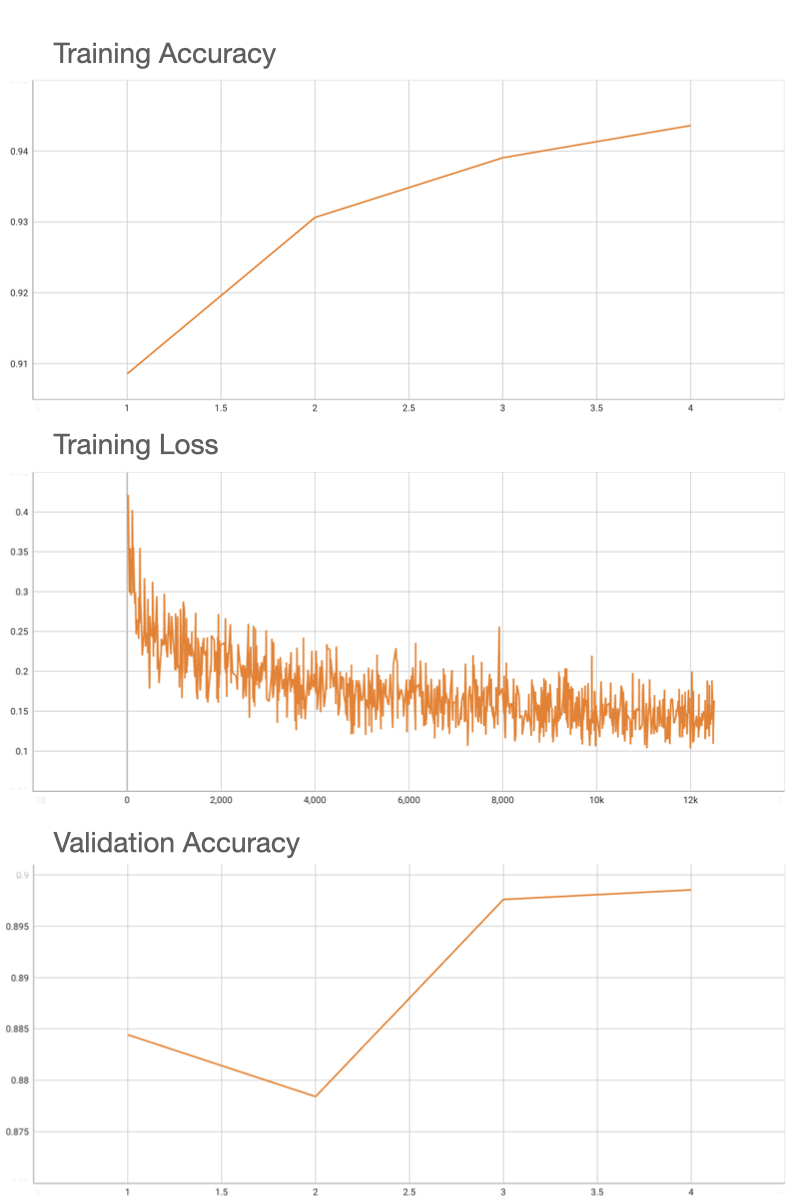
Performance
FROC score is used for evaluating the performance of the model. After inference is done, evaluate_froc.sh needs to be run to evaluate FROC score based on predicted probability map (output of inference) and the ground truth tumor masks.
Using an internal pretrained weights for ResNet18, this model deterministically achieves the 0.90 accuracy on validation patches, and FROC of 0.72 on the 48 Camelyon testing data that have ground truth annotations available.
The pathology_tumor_detection bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
Please notice that the benchmark results are tested on one WSI image since the images are too large to benchmark. And the inference time in the end-to-end line stands for one patch of the whole image.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16 |
|---|---|---|---|---|---|---|---|---|
| model computation | 1.93 | 2.52 | 1.61 | 1.33 | 0.77 | 1.20 | 1.45 | 1.89 |
| end2end | 224.97 | 223.50 | 222.65 | 224.03 | 1.01 | 1.01 | 1.00 | 1.00 |
Where:
model computationmeans the speedup ratio of model's inference with a random input without preprocessing and postprocessingend2endmeans run the bundle end-to-end with the TensorRT based model.torch_fp32andtorch_ampare for the PyTorch models with or withoutampmode.trt_fp32andtrt_fp16are for the TensorRT based models converted in corresponding precision.speedup amp,speedup fp32andspeedup fp16are the speedup ratios of corresponding models versus the PyTorch float32 modelamp vs fp16is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the MONAI Bundle Configuration Page.
Execute training
python -m monai.bundle run --config_file configs/train.json
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using --dataset_dir:
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
Override the train config to execute multi-GPU training
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove --standalone, modify --nnodes, or do some other necessary changes according to the machine used. For more details, please refer to pytorch's official tutorial.
Note: When using a container based on PyTorch 24.0x, you may encounter random NCCL timeout errors. To address this issue, consider the following adjustments:
- Reduce the
num_workers: Decreasing the number of data loader workers can help minimize these errors. - Set
pin_memorytoFalse: Disabling pinned memory may reduce the likelihood of timeouts. - Switch to the
gloobackend: As a workaround, you can set the distributed training backend toglooto avoid NCCL-related timeouts.
You can implement these settings by adding flags like --train#dataloader#num_workers 0 or --train#dataloader#pin_memory false.
Execute inference
CUDA_LAUNCH_BLOCKING=1 python -m monai.bundle run --config_file configs/inference.json
Evaluate FROC metric
cd scripts && source evaluate_froc.sh
Export checkpoint to TorchScript file
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
Export checkpoint to TensorRT based models with fp32 or fp16 precision
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --dynamic_batchsize "[1, 400, 600]"
Execute inference with the TensorRT model
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
References
[1] He, Kaiming, et al, "Deep Residual Learning for Image Recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016. https://arxiv.org/pdf/1512.03385.pdf
License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.