FoundationPose is a unified foundation model for 6D object pose estimation and tracking of objects.
Model Overview
The FoundationPose [1] model described in this model card estimates the 6D pose of a specific object passed into the network as input. The input contains the object’s image, depth map, and 3D model of the object. The output from the network is the estimated vector containing the pose and tracking of the object. When a 3D model of the object is not available, FoundationPose can use a few images of the object with corresponding depth map instead. The FoundationPose model is fully trained and does not require additional training for commercial applications.


Figure 1. FoundationPose real time pose estimates of grocery products for robot manipulation on the left, and mobile robot charging dock pose estimate on the right.
Model Architecture
FoundationPose is a DNN model trained to estimate and track the orientation and position of objects and corresponding parts. The architecture consists of three aggregated modules. The first is a pose refinement network, the second module is a pose selection network and lastly, an optional object modeling neural field to render unknown or model-free objects. The object modeling neural field uses a signed distance function (SDF) [4] to approximate a neural object field for model-free objects without CAD model. The SDF is an implicit MLP network that maps any 3D point location to a signed distance value. During training, we first sample a group of coarse global poses from the input. The input is further rendered by the object modeling neural field to obtain a RGBD rendering field. The rendered field is passed to the pose refinement network together with additional crops of input observation from the camera that captures surrounding contexts around the object. Lastly, the refinement network outputs some hypotheses poses and the pose selection network selects the best pose. See Figure 1 for illustration.
How to Use this Model
Our model can be deployed in a wide variety of scenarios including robotic arm manipulation tasks, autonomous robot navigation, target tracking in delivery robots and so on. The model is intended to be run using NVIDIA hardware and software. For hardware, the model can run on any NVIDIA GPU including NVIDIA Jetson devices. The model is intended for Ubuntu 22.04 with CUDA 11.6 or Jetpack 6.0 DP and later. This model can only be used with TensorRT.
Instructions to Convert Model to TensorRT Engine Plan
This model is distributed in two formats. Version 1.0.0 contains encrypted ETLT files, while version 1.0.0_onnx contains the same model weights in an unencrypted ONNX format.
Using ONNX: This model can be used in its unencrypted format as-is. However, the onnx files can also be converted to TensorRT engine plans using trtexec for better performance.
trtexec --onnx=./refine_model.onnx --saveEngine=./refine_trt_engine.plan --minShapes=input1:1x160x160x6,input2:1x160x160x6 --optShapes=input1:1x160x160x6,input2:1x160x160x6 --maxShapes=input1:252x160x160x6,input2:252x160x160x6
trtexec --onnx=./score_model.onnx --saveEngine=./score_trt_engine.plan --minShapes=input1:1x160x160x6,input2:1x160x160x6 --optShapes=input1:1x160x160x6,input2:1x160x160x6 --maxShapes=input1:252x160x160x6,input2:252x160x160x6
Using ETLT: In order to use the model in this encrypted format, convert the two etlt files to TensorRT engine plans using TAO. The model is encrypted and will only operate with the key foundationpose. Please make sure to use this key with the TAO command to convert it into a TensorRT engine plan.
tao-converter -k foundationpose -t fp16 -e ./refine_trt_engine.plan -p input1,1x160x160x6,1x160x160x6,252x160x160x6 -p input2,1x160x160x6,1x160x160x6,252x160x160x6 -o output1,output2 refine_model.etlt
tao-converter -k foundationpose -t fp16 -e ./score_trt_engine.plan -p input1,1x160x160x6,1x160x160x6,252x160x160x6 -p input2,1x160x160x6,1x160x160x6,252x160x160x6 -o output1 score_model.etlt
FoundationPose is accessible in Isaac-ROS under isaac_ros_foundationpose. It seamlessly integrates both the refinement and score model inference, along with all required preprocessing and postprocessing to deliver the accurate pose estimation. To run the FoudationPose ROS node, please refer to the quickstart available in isaac_ros_docs.
sample inference results
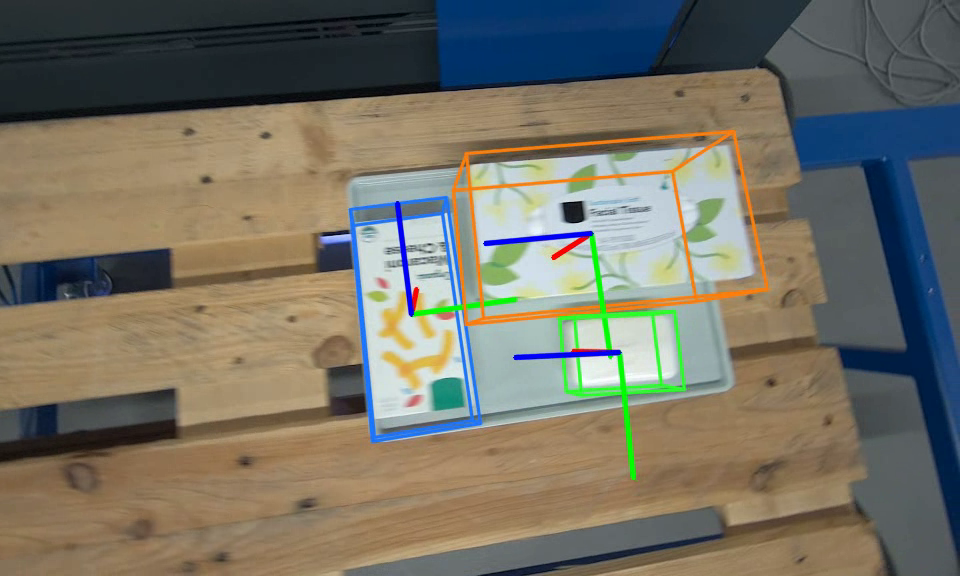
Training
During training, we first pretrain the neural object field, pose refine network, and pose ranking network separately. We then freeze the neural object field network and finetune the other modules in the network. We model weights are updated during training to minimize the following objective loss functions: A contrastive loss and a cross-entropy loss function.
Dataset


The foundation pose model is trained on a dataset of 678,000 images with ground truth. Each image contains multiple object poses. The dataset is augmented with 8 permutations during training for a total of 5.4 million images. The dataset was synthetically generated with Isaac Sim, using 41K object models from Objaverse [2] and 1K object models from GSO [3]. Images are generated to include textures from real photographs rendered into the scenes.
Key Performance Indicators (KPIs)
We compare the performance of foundation-pose with other state of the art pose estimation models. Table 1.0 shows quantitative numbers on the standard BOP challenge benchmark for 6D Object Pose Estimation. The number comparison is made on this dataset without additional finetuning on the target dataset. FoundationPose was the #1 ranked solution in March 2024 for unseen objects (no studying for the test).
| Method | Test image | core | LM-o | T-LESS | TUD-L | IC-BIN | ITODD | HB | YCB-V |
|---|---|---|---|---|---|---|---|---|---|
| Our Model | RGB-D | 0.726 | 0.733 | 0.617 | 0.906 | 0.528 | 0.609 | 0.809 | 0.882 |
Table 1.0 Showing 6D localization of unseen objects – Core datasets results for FoundationPose.
Realtime Inference Performance
Furthermore, we assess real time inference performance in queries per seconds (QPS) for FoundationPose in FP16 precision. The following profiling numbers are obtained using tensorrt’s trtexec tool on Jetson Orin and RTX 4090 GPU.
| Platform | Pose Estimation (QPS) | Pose Tracking (QPS) |
|---|---|---|
| Jetson Orin | 4.6 | 746.0 |
| RTX 4090 | - | - |
| RTX 4060Ti | 8.7 | 1599.4 |
Table 2.0 Showing Inference performance numbers on NVIDIA Jetson AGX Orin, RTX 4090, and RTX 4060Ti.
Limitations
Our FoundationPose model may have poor depth prediction for highly reflective or transparent objects causing the model to predict the incorrect object poses. Although, our model is robust to blurry images, accutely blurry objects in an scene may also lead to poor pose and tracking performance.
References
[1] Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield (2023). FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects.
[2] Objaverse 1.0 for 3D object models.
[3] Downs, Laura, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Reymann, Thomas B. McHugh, and Vincent Vanhoucke. "Google scanned objects: A high-quality dataset of 3d scanned household items." In 2022 International Conference on Robotics and Automation (ICRA), pp. 2553-2560. IEEE, 2022.
[4] Wen, Bowen, et al. "Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
License
License to use this model is covered by the Model EULA. By downloading the public and release version of the model, you accept the terms and conditions of these licenses.
Ethical Considerations
We do not use any real images in training Foundation Pose. All training dataset were synthetically generated using Isaac Sim. Hence, the semantic content of the input data does not contain any real person, place or identifiable information. The network learns geometry, and appearance and predicts poses of objects from only the generated synthetic dataset with no personal identifiable information. Thus, there are no ethical concerns for this work..
Acknowledgements
We acknowledge and thank the sources of assets used to render scenes and objects featured in our datasets in this attribution list.