A framework for self-supervised learning of speech representations which masks latent representations of the raw waveform and solves a contrastive task over quantized speech representations.
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA's latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark the training performance with a number of specific configurations, run:
NUM_GPUS=[NUM] UPDATE_FREQ=[NUM] NUM_CONCAT_BATCHES=[NUM] NUM_EPOCHS=[NUM] NUM_WARUP_EPOCHS=[NUM] \
BF16=[true|false] FP16=[true|false] bash scripts/pretrain_base_benchmark.sh
NUM_GPUS=[NUM] UPDATE_FREQ=[NUM] NUM_CONCAT_BATCHES=[NUM] NUM_EPOCHS=[NUM] NUM_WARUP_EPOCHS=[NUM] \
BF16=[true|false] FP16=[true|false] bash scripts/finetune_base_benchmark.sh
for example:
NUM_GPUS=8 UPDATE_FREQ=1 NUM_CONCAT_BATCHES=8 BF16=true bash scripts/pretrain_base_benchmark.sh
NUM_GPUS=8 UPDATE_FREQ=1 NUM_CONCAT_BATCHES=1 BF16=true bash scripts/finetune_base_benchmark.sh
By default, these scripts run initially for NUM_WARMUP_EPOCHS=2, and collect performance results for another NUM_EPOCHS=5 on the train-clean-100 subset of LibriSpeech.
Inference performance benchmark
To benchmark the inference performance on a specific batch size, run:
NUM_WARMUP_REPEATS=[NUM] NUM_REPEATS=[NUM] BATCH_SIZE=[NUM] BF16=[true|false] FP16=[true|false] \
bash scripts/inference_benchmark.sh
for example:
NUM_WARMUP_REPEATS=2 NUM_REPEATS=10 BATCH_SIZE=8 BF16=true bash scripts/inference_benchmark.sh
By default, the model will process all samples in the test-other subset of LibriSpeech initially NUM_WARMUP_REPEATS times for warmup,
and then NUM_REPEATS times recording the measurements. The number of iterations will depend on the batch size.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
Pre-training results were obtained by running the scripts/pretrain_base.sh training script in the PyTorch 22.11-py3 NGC container on NVIDIA A100 (8x A100 80GB) GPUs.
We report a median of eight (BF16 mixed precision) and three (TF32) runs.
| GPUs | (Concatenated) batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 8 x 1400k max tokens | 0.619 | 0.633 | 64.9 h | 48.1 h | 1.35 |
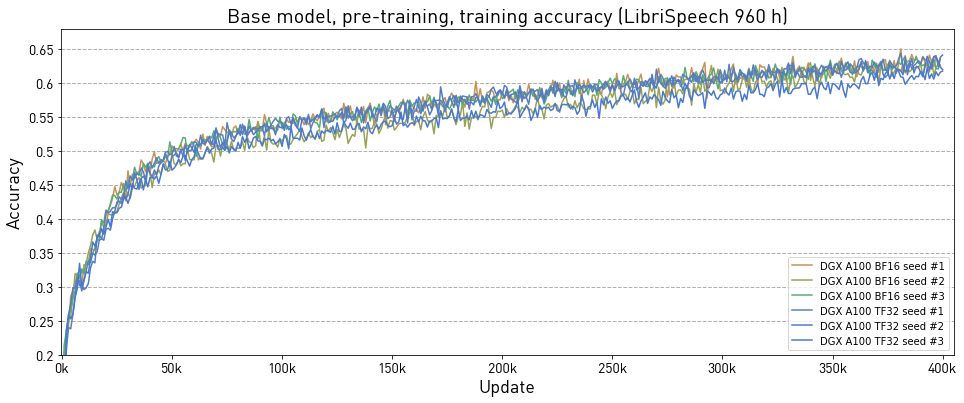
Fine-tuning results were obtained by running the scripts/finetune_base_960h.sh training script in the PyTorch 22.11-py3 NGC container on NVIDIA A100 (8x A100 80GB) GPUs.
We report a median of eight runs; each resumed from a different pre-training checkpoint.
| GPUs | (Concatenated) batch size / GPU | WER - mixed precision | Time to train - TF32 | Time to train - mid precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|
| 8 | 1 x 3200k max tokens | 8.878 | 8.2 h | 6.5 h | 1.27 |
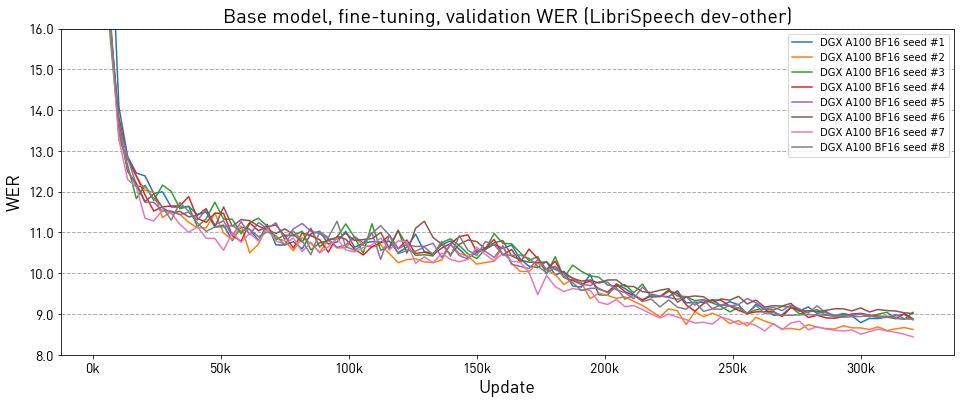
Training stability test
The wav2vec 2.0 Base model was pre-trained with eight different initial random seeds in bfloat16 precision in the PyTorch 22.11-py3 NGC container on NVIDIA DGX A100 with 8x A100 80GB.
Below we present accuracy of this model in the self-training task:
| Update | Average | Std | Min | Max | Median |
|---|---|---|---|---|---|
| 50k | 0.491 | 0.011 | 0.471 | 0.514 | 0.493 |
| 100k | 0.537 | 0.009 | 0.518 | 0.550 | 0.539 |
| 150k | 0.564 | 0.009 | 0.544 | 0.577 | 0.564 |
| 200k | 0.580 | 0.009 | 0.558 | 0.589 | 0.583 |
| 250k | 0.599 | 0.008 | 0.586 | 0.607 | 0.602 |
| 300k | 0.610 | 0.010 | 0.589 | 0.622 | 0.611 |
| 350k | 0.619 | 0.009 | 0.607 | 0.634 | 0.617 |
| 400k | 0.629 | 0.007 | 0.614 | 0.636 | 0.633 |
Afterward, each of those runs was fine-tuned on LibriSpeech 960 h dataset with yet another different initial random seed.
Below we present the word error rate (WER) on the dev-other subset of LibriSpeech:
| Update | Average | Std | Min | Max | Median |
|---|---|---|---|---|---|
| 50k | 11.198 | 0.303 | 10.564 | 11.628 | 11.234 |
| 100k | 10.825 | 0.214 | 10.574 | 11.211 | 10.763 |
| 150k | 10.507 | 0.160 | 10.224 | 10.778 | 10.518 |
| 200k | 9.567 | 0.186 | 9.235 | 9.836 | 9.530 |
| 250k | 9.115 | 0.193 | 8.764 | 9.339 | 9.194 |
| 300k | 8.885 | 0.201 | 8.507 | 9.151 | 8.972 |
| 320k | 8.827 | 0.188 | 8.440 | 9.043 | 8.878 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 80GB)
Pre-training
Our results were obtained by running the scripts/pretrain_base_benchmark.sh training script in the PyTorch 22.11-py3 NGC container on NVIDIA A100 (8x A100 80GB) GPUs. Performance numbers in transformer tokens per second were averaged over an entire training epoch.
| GPUs | Concat batches / GPU | Grad accumulation | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 to mixed precision) | Strong scaling - TF32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|---|
| 1 | 8 | 8 | 28045.27 | 37609.84 | 1.34 | 1.00 | 1.00 |
| 4 | 8 | 2 | 103842.47 | 138956.38 | 1.34 | 3.70 | 3.69 |
| 8 | 8 | 1 | 194306.46 | 261881.29 | 1.35 | 6.93 | 6.96 |
To achieve these same results, follow the steps in the Quick Start Guide.
Fine-tuning
Our results were obtained by running the scripts/finetune_base_benchmark.sh training script in the PyTorch 22.11-py3 NGC container on NVIDIA A100 (8x A100 80GB) GPUs. Performance numbers in transformer tokens per second were averaged over an entire training epoch.
| GPUs | Concat batches / GPU | Grad accumulation | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 to mixed precision) | Strong scaling - TF32 | Strong scaling - mixed precision |
|---|---|---|---|---|---|---|---|
| 1 | 8 | 1 | 34813.46 | 41275.76 | 1.19 | 1.00 | 1.00 |
| 4 | 2 | 1 | 102326.57 | 132361.62 | 1.29 | 2.94 | 3.21 |
| 8 | 1 | 1 | 163610.16 | 207200.91 | 1.27 | 4.70 | 5.02 |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 80GB)
Our results were obtained by running the scripts/inference_benchmark.sh inferencing benchmarking script in the PyTorch 22.11-py3 NGC container on the NVIDIA A100 (1x A100 80GB) GPU.
The script runs inference on the test-other subset of LibriSpeech in variable-length batches.
| Duration | BF16 Latency (ms) Percentiles | TF32 Latency (ms) Percentiles | BF16/TF32 speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BS | Avg | 90% | 95% | 99% | Avg | 90% | 95% | 99% | Avg | Avg |
| 1 | 6.54 s | 11.02 | 11.41 | 12.42 | 10.45 | 10.88 | 11.23 | 12.51 | 10.31 | 0.99 |
| 4 | 6.54 s | 21.74 | 24.12 | 35.80 | 17.69 | 23.17 | 26.85 | 41.62 | 18.42 | 1.04 |
| 8 | 6.54 s | 40.06 | 48.07 | 74.59 | 28.70 | 46.43 | 54.86 | 88.73 | 31.30 | 1.09 |
| 16 | 6.54 s | 88.78 | 117.40 | 151.37 | 58.82 | 102.64 | 135.92 | 175.68 | 67.44 | 1.15 |
To achieve these same results, follow the steps in the Quick Start Guide.