A framework for self-supervised learning of speech representations which masks latent representations of the raw waveform and solves a contrastive task over quantized speech representations.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
This repository provides an optimized implementation of the wav2vec 2.0 model, as described in the paper wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. It is based on the Fairseq codebase published by the authors of the paper. The wav2vec 2.0 model is pre-trained unsupervised on large corpora of speech recordings. Afterward, it can be quickly fine-tuned in a supervised way for speech recognition or serve as an extractor of high-level features and pseudo-phonemes for other applications.
The differences between this wav2vec 2.0 and the reference implementation are:
- Support for increased batch size, which does not change batch-dependent constants for negative sampling and loss calculation and improves hardware utilization
- Support for the Hourglass Transformer architecture, which in the default setting improves the training speed of the
Basemodel by 1.4x, lowers memory consumption by 38%, and retains accuracy
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta, NVIDIA Turning, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 1.35x faster than training without Tensor Cores while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
The model takes raw waveforms as its input. A fully convolutional feature extractor reduces the resolution of the signal to a single vector roughly every 20 ms. Most of the computation is performed in the transformer encoder part of the model. The outputs of the transformer, and quantized outputs from the feature extractor, serve as inputs to the contrastive loss. During fine-tuning, this loss is replaced with the CTC loss, and quantization is not performed.
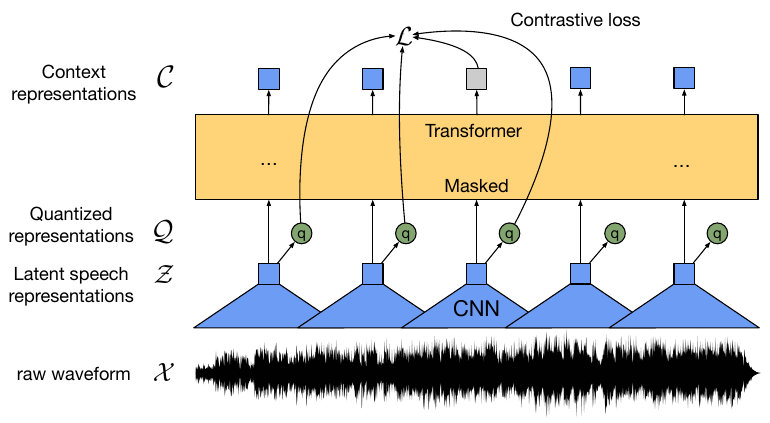
Figure 1. The architecture of wav2vec 2.0 ([source](https://proceedings.neurips.cc/paper/2020/file/92d1e1eb1cd6f9fba3227870bb6d7f07-Paper.pdf)). The model is composed of a convolutional feature extractor, and a transformer encoder. During fine-tuning, quantization is disabled and contrastive loss is replaced with the CTC loss function.
In addition, our model uses the Hourglass Transformer architecture for the encoder. This architecture uses fixed-sized pooling in order to reduce the time dimension T of the signal, and thus, lower the O(T²) cost of the self-attention mechanism.
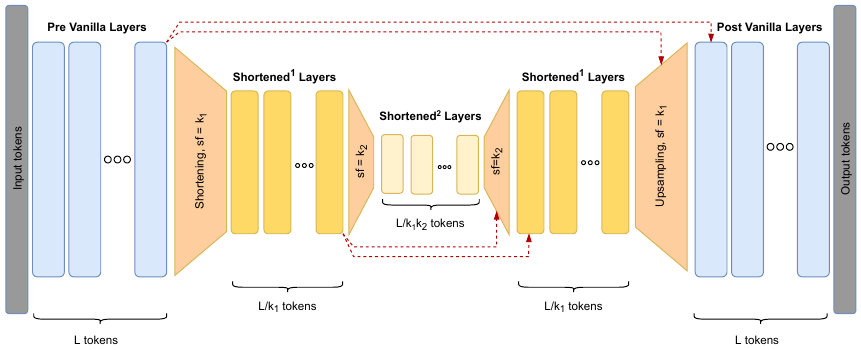
Figure 2. The Hourglass Transformer module ([source](https://arxiv.org/abs/2110.13711)). The signal is processed by the initial layers and downsampled. Most of the layers operate on the downsampled signal. Finally, the signal is upsampled for the final layers. The Hourglass Transformer replaced a regular stack of transformer layers, typically improving throughput and lowering memory consumption.
Default configuration
The following features were implemented in this model:
- general:
- multi-GPU and multi-node training
- Hourglass Transformer architecture
- dynamic loss scaling with backoff for tensor cores (mixed precision) training
- mixed-precision training with
O2optimization level, based on float16 or bfloat16
- training:
- support for variable batch size without changing batch-dependent constants for the loss function
- inference:
- masking for inference with a larger batch
Our main recipes replicate the Base model described in the wav2vec 2.0 paper, and use Hourglass Transformer with pooling factor 4. Note that Hourglass Transformer can be entirely disabled and this codebase is compatible with Fairseq checkpoints.
Below we present performance numbers for the Hourglass Transformer with different pooling factors (Base model, pre-training, A100 80GB GPU, bfloat16):
| Configuration | Throughput speedup | GPU memory (% of Baseline) |
|---|---|---|
| Baseline | 1.00 | 100.00% |
| Hourglass factor=2 | 1.25 | 70.98% |
| Hourglass factor=3 | 1.33 | 64.31% |
| Hourglass factor=4 (default) | 1.37 | 62.35% |
| Hourglass factor=5 | 1.39 | 60.00% |
| Hourglass factor=6 | 1.40 | 59.61% |
Feature support matrix
This model supports the following features:
| Feature | wav2vec 2.0 |
|---|---|
| Multi-node training | yes |
| Automatic mixed precision (AMP) | yes |
Features
Automatic Mixed Precision (AMP) This implementation uses automatic mixed-precision training ported from Fairseq. It allows us to use FP16 or BF16 training with FP16 master weights.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in NVIDIA Volta, and following with both the NVIDIA Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
Enabling mixed precision
For training and inference, mixed precision can be enabled by adding the --fp16 flag or --bf16 flag, depending on the target's lower precision. NVIDIA Ampere and later architectures provide hardware support for bfloat16, which is beneficial for this model, as it skips certain stabilizing FP32 casts. For NVIDIA Volta and NVIDIA Turing architectures, select --fp16.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Brain Floating Point (bfloat16) A 16-bit floating point format that uses an 8-bit exponent, a 7-bit fraction, and a sign bit. Contrary to float16, which uses a 5-bit exponent, bfloat16 retains the same exponent precision as float32, and its robustness with respect to wide ranges of values during training.
Fine-tuning Training an already pretrained model further using a task-specific dataset for subject-specific refinements by adding task-specific layers on top if required.
Hourglass Transformer Architecture proposed in the paper Hierarchical Transformers Are More Efficient Language Models, which improves resource consumption of a stack of transformer layers, in many cases retaining the accuracy.
Pre-training Training a model on vast amounts of data on the same (or different) task to build general understandings.
Transformer The paper Attention Is All You Need introduces a novel architecture called transformer that uses an attention mechanism and transforms one sequence into another.
Connectionist Temporal Classification (CTC) Loss A loss function introduced in Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. It calculates the probability of all valid output sequences with repetitions, and allows to train end-to-end ASR models without any prior alignments of transcriptions to audio.