U-Net allows for seamless segmentation of 2D images, with high accuracy and performance.
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA's latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark training, run one of the TRAIN_BENCHMARK scripts in ./examples/:
bash examples/unet_TRAIN_BENCHMARK{_TF-AMP}_{1, 8}GPU.sh <path/to/dataset> <path/to/checkpoint> <batch/size>
For example, to benchmark training using mixed-precision on 8 GPUs use:
bash examples/unet_TRAIN_BENCHMARK_TF-AMP_8GPU.sh <path/to/dataset> <path/to/checkpoint> <batch/size>
Each of these scripts will by default run 200 warm-up iterations and benchmark the performance during training in the next 800 iterations.
To have more control, you can run the script by directly providing all relevant run parameters. For example:
horovodrun -np <num/of/gpus> python main.py --exec_mode train --benchmark --augment --data_dir <path/to/dataset> --model_dir <optional, path/to/checkpoint> --batch_size <batch/size> --warmup_steps <warm-up/steps> --max_steps <max/steps>
At the end of the script, a line reporting the best train throughput will be printed.
Inference performance benchmark
To benchmark inference, run one of the scripts in ./examples/:
bash examples/unet_INFER_BENCHMARK{_TF-AMP}.sh <path/to/dataset> <path/to/checkpoint> <batch/size>
For example, to benchmark inference using mixed-precision:
bash examples/unet_INFER_BENCHMARK_TF-AMP.sh <path/to/dataset> <path/to/checkpoint> <batch/size>
Each of these scripts will by default run 200 warm-up iterations and benchmark the performance during inference in the next 400 iterations.
To have more control, you can run the script by directly providing all relevant run parameters. For example:
python main.py --exec_mode predict --benchmark --data_dir <path/to/dataset> --model_dir <optional, path/to/checkpoint> --batch_size <batch/size> --warmup_steps <warm-up/steps> --max_steps <max/steps>
At the end of the script, a line reporting the best inference throughput will be printed.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
The following table lists the average DICE score across 5-fold cross-validation. Our results were obtained by running the examples/unet_TRAIN{_TF-AMP}_{1, 8}GPU.sh training script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs.
| GPUs | Batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 [min] | Time to train - mixed precision [min] | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 8 | 0.8908 | 0.8910 | 22 | 10 | 2.2 |
| 8 | 8 | 0.8938 | 0.8942 | 2.6 | 2.5 | 1.04 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
The following table lists the average DICE score across 5-fold cross-validation. Our results were obtained by running the examples/unet_TRAIN_{FP32, TF-AMP}_{1, 8}GPU.sh training script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs.
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 [min] | Time to train - mixed precision [min] | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 8 | 0.8910 | 0.8903 | 48 | 19 | 2.53 |
| 8 | 8 | 0.8942 | 0.8940 | 7 | 7.5 | 0.93 |
To reproduce this result, start the Docker container interactively and run one of the TRAIN scripts:
bash examples/unet_TRAIN{_TF-AMP}_{1, 8}GPU.sh <path/to/dataset> <path/to/checkpoint> <batch/size>
for example
bash examples/unet_TRAIN_TF-AMP_8GPU.sh /data /results 8
This command will launch a script which will run 5-fold cross-validation training for 40,000 iterations and print the validation DICE score and cross-entropy loss. The time reported is for one fold, which means that the training for 5 folds will take 5 times longer. The default batch size is 8, however if you have less than 16 Gb memory card and you encounter GPU memory issue you should decrease the batch size. The logs of the runs can be found in /results directory once the script is finished.
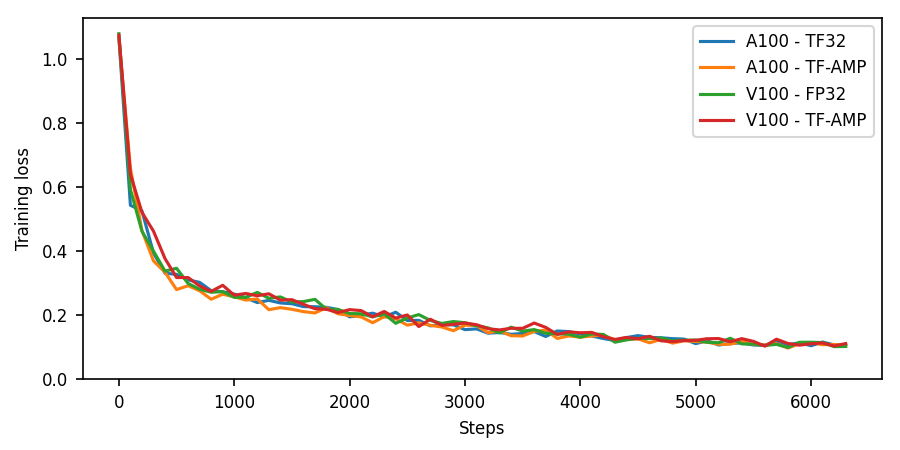
Learning curves
The following image show the training loss as a function of iteration for training using DGX A100 (TF32 and TF-AMP) and DGX-1 V100 (FP32 and TF-AMP).
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 40GB)
Our results were obtained by running the examples/unet_TRAIN_BENCHMARK{_TF-AMP}_{1, 8}GPU.sh training script in the examples/unet_TRAIN_BENCHMARK_{TF-AMP, FP32}_{1, 8}GPU.sh NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs. Performance numbers (images per second) were averaged over 1000 iterations, excluding the first 200 warm-up steps.
| GPUs | Batch size / GPU | Throughput - TF32 [img/s] | Throughput - mixed precision [img/s] | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 1 | 29.81 | 64.22 | 2.15 | - | - |
| 1 | 8 | 40.50 | 120.08 | 2.58 | - | - |
| 8 | 1 | 169.62 | 293.31 | 1.73 | 5.69 | 4.57 |
| 8 | 8 | 304.64 | 738.64 | 2.42 | 6.55 | 6.15 |
Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the examples/unet_TRAIN_BENCHMARK{_TF-AMP}_{1, 8}GPU.sh training script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs. Performance numbers (in images per second) were averaged over 1000 iterations, excluding the first 200 warm-up steps.
| GPUs | Batch size / GPU | Throughput - FP32 [img/s] | Throughput - mixed precision [img/s] | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 1 | 15.70 | 39.62 | 2.52 | - | - |
| 1 | 8 | 18.85 | 60.28 | 3.20 | - | - |
| 8 | 1 | 102.52 | 212.51 | 2.07 | 6.53 | 5.36 |
| 8 | 8 | 141.75 | 403.88 | 2.85 | 7.52 | 6.70 |
To achieve these same results, follow the steps in the Training performance benchmark section.
Throughput is reported in images per second. Latency is reported in milliseconds per image.
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 40GB)
Our results were obtained by running the examples/unet_INFER_BENCHMARK{_TF-AMP}.sh inferencing benchmarking script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX A100 (1x A100 40GB) GPU.
FP16
| Batch size | Resolution | Throughput Avg [img/s] | Latency Avg [ms] | Latency 90% [ms] | Latency 95% [ms] | Latency 99% [ms] |
|---|---|---|---|---|---|---|
| 1 | 572x572x1 | 251.11 | 3.983 | 3.990 | 3.991 | 3.993 |
| 2 | 572x572x1 | 179.70 | 11.130 | 11.138 | 11.139 | 11.142 |
| 4 | 572x572x1 | 197.53 | 20.250 | 20.260 | 20.262 | 20.266 |
| 8 | 572x572x1 | 382.48 | 24.050 | 29.356 | 30.372 | 32.359 |
| 16 | 572x572x1 | 400.58 | 45.759 | 55.615 | 57.502 | 61.192 |
TF32
| Batch size | Resolution | Throughput Avg [img/s] | Latency Avg [ms] | Latency 90% [ms] | Latency 95% [ms] | Latency 99% [ms] |
|---|---|---|---|---|---|---|
| 1 | 572x572x1 | 88.80 | 11.261 | 11.264 | 11.264 | 11.265 |
| 2 | 572x572x1 | 104.62 | 19.120 | 19.149 | 19.155 | 19.166 |
| 4 | 572x572x1 | 117.02 | 34.184 | 34.217 | 34.223 | 34.235 |
| 8 | 572x572x1 | 131.54 | 65.094 | 72.577 | 74.009 | 76.811 |
| 16 | 572x572x1 | 137.41 | 121.552 | 130.795 | 132.565 | 136.027 |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
Our results were obtained by running the examples/unet_INFER_BENCHMARK{_TF-AMP}.sh inferencing benchmarking script in the tensorflow:20.06-tf1-py3 NGC container on NVIDIA DGX-1 with (1x V100 16GB) GPU.
FP16
| Batch size | Resolution | Throughput Avg [img/s] | Latency Avg [ms] | Latency 90% [ms] | Latency 95% [ms] | Latency 99% [ms] |
|---|---|---|---|---|---|---|
| 1 | 572x572x1 | 127.11 | 7.868 | 7.875 | 7.876 | 7.879 |
| 2 | 572x572x1 | 140.32 | 14.256 | 14.278 | 14.283 | 14.291 |
| 4 | 572x572x1 | 148.28 | 26.978 | 27.005 | 27.010 | 27.020 |
| 8 | 572x572x1 | 178.28 | 48.432 | 54.613 | 55.797 | 58.111 |
| 16 | 572x572x1 | 181.94 | 94.812 | 106.743 | 109.028 | 113.496 |
FP32
| Batch size | Resolution | Throughput Avg [img/s] | Latency Avg [ms] | Latency 90% [ms] | Latency 95% [ms] | Latency 99% [ms] |
|---|---|---|---|---|---|---|
| 1 | 572x572x1 | 47.32 | 21.133 | 21.155 | 21.159 | 21.167 |
| 2 | 572x572x1 | 51.43 | 38.888 | 38.921 | 38.927 | 38.940 |
| 4 | 572x572x1 | 53.56 | 74.692 | 74.763 | 74.777 | 74.804 |
| 8 | 572x572x1 | 54.41 | 152.733 | 163.148 | 165.142 | 169.042 |
| 16 | 572x572x1 | 67.11 | 245.775 | 259.548 | 262.186 | 267.343 |
To achieve these same results, follow the steps in the Inference performance benchmark section.
Throughput is reported in images per second. Latency is reported in milliseconds per batch.