This model is a convolutional neural network for 2D image segmentation tuned to avoid overfitting.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
This UNet model is adapted from the original version of the UNet model which is a convolutional auto-encoder for 2D image segmentation. UNet was first introduced by Olaf Ronneberger, Philip Fischer, and Thomas Brox in the paper: UNet: Convolutional Networks for Biomedical Image Segmentation.
This work proposes a modified version of UNet, called TinyUNet which performs efficiently and with very high accuracy
on the industrial anomaly dataset DAGM2007.
TinyUNet, like the original UNet is composed of two parts:
- an encoding sub-network (left-side)
- a decoding sub-network (right-side).
It repeatedly applies 3 downsampling blocks composed of two 2D convolutions followed by a 2D max pooling layer in the encoding sub-network. In the decoding sub-network, 3 upsampling blocks are composed of a upsample2D layer followed by a 2D convolution, a concatenation operation with the residual connection and two 2D convolutions.
TinyUNet has been introduced to reduce the model capacity which was leading to a high degree of over-fitting on a
small dataset like DAGM2007. The complete architecture is presented in the figure below:
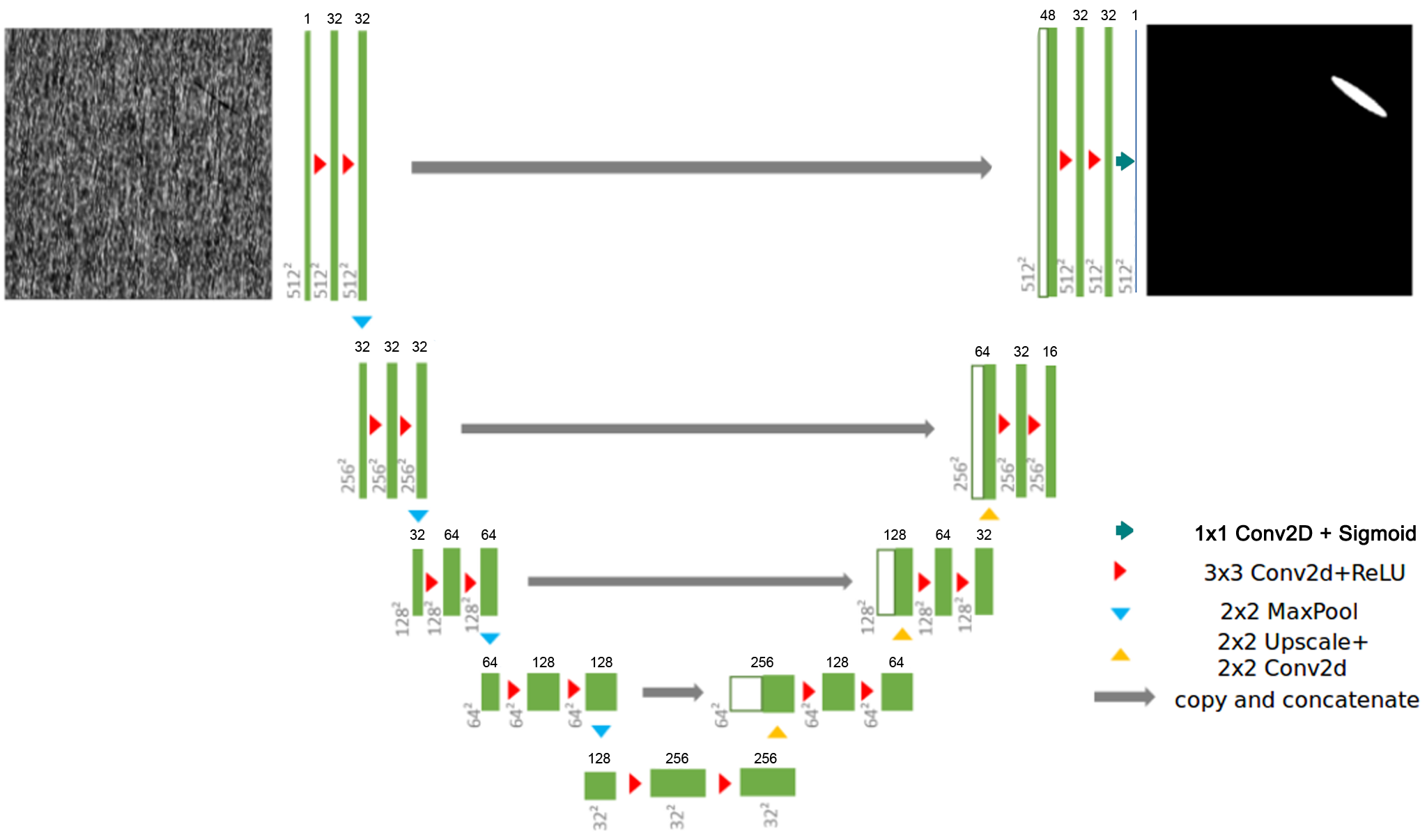
Figure 1. Architecture of the UNet Industrial
Default Configuration
This model trains in 2500 epochs, under the following setup:
-
Global Batch Size: 16
-
Optimizer RMSProp:
- decay: 0.9
- momentum: 0.8
- centered: True
-
Learning Rate Schedule: Exponential Step Decay
- decay: 0.8
- steps: 500
- initial learning rate: 1e-4
-
Weight Initialization: He Uniform Distribution (introduced by Kaiming He et al. in 2015 to address issues related ReLU activations in deep neural networks)
-
Loss Function: Adaptive
- When DICE Loss < 0.3, Loss = Binary Cross Entropy
- Else, Loss = DICE Loss
-
Data Augmentation
- Random Horizontal Flip (50% chance)
- Random Rotation 90°
-
Activation Functions:
- ReLU is used for all layers
- Sigmoid is used at the output to ensure that the ouputs are between [0, 1]
-
Weight decay: 1e-5
Feature support matrix
The following features are supported by this model.
| Feature | UNet Medical |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Horovod Multi-GPU (NCCL) | Yes |
| Accelerated Linear Algebra (XLA) | Yes |
Features
Automatic Mixed Precision (AMP)
This implementation of UNet uses AMP to implement mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just a few lines of code.
Horovod
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Multi-GPU training with Horovod
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
XLA support (experimental)
XLA is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes. The results are improvements in speed and memory usage: most internal benchmarks run ~1.1-1.5x faster after XLA is enabled.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta and Turing GPUs automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
This implementation exploits the TensorFlow Automatic Mixed Precision feature. In order to enable mixed precision training, the following environment variables must be defined with the correct value before the training starts:
TF_ENABLE_AUTO_MIXED_PRECISION=1
Exporting these variables ensures that loss scaling is performed correctly and automatically.
By supplying the --amp flag to the main.py script while training in FP32, the following variables are set to their correct value for mixed precision training:
if params.use_amp:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.