Transformer-XL is a transformer-based language model with a segment-level recurrence and a novel relative positional encoding.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
This repository provides an implementation of the Transformer-XL model in TensorFlow from the paper Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. Transformer-XL is a transformer-based language model with a segment-level recurrence and a novel relative positional encoding. Enhancements introduced in Transformer-XL help capture better long-term dependencies by attending to tokens from multiple previous segments.
Our implementation is based on the codebase published by the authors of the Transformer-XL paper. Our implementation uses a modified model architecture. Our modifications were made to achieve better hardware utilization and to take advantage of Tensor Cores. Similar modifications were also proposed in an implementation available from github.com/cybertronai/transformer-xl. Refer to the Model architecture section for more details.
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 1.5x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
The Transformer-XL "base" model for WikiText-103 dataset available in this repository was modified to use the following hyperparameter values:
| Hyperparameter | Description | Original setting for the base model | Our modification to the base model |
|---|---|---|---|
d_model | hidden size | 410 | 512 |
n_head | number of attention heads | 10 | 8 |
d_head | size of each attention head | 41 | 64 |
d_inner | hidden size in fully-connected layers | 2100 | 2048 |
tgt_len | number of tokens to predict during training | 150 | 192 |
mem_len | number of tokens cached from previous iterations during training | 150 | 192 |
Changes described above were made to align certain hyperparameters with powers of two, with this modification, the model is able to achieve better hardware utilization, and therefore higher training throughput.
The following table lists the hyperparameters for the base Transformer-XL model for WikiText-103 dataset available in this repository.
| Hyperparameter | Description | Base model |
|---|---|---|
n_layer | number of layers | 16 |
d_model | hidden size | 512 |
n_head | number of attention heads | 8 |
d_head | size of each attention head | 64 |
d_inner | inner hidden size in fully-connected layers | 2048 |
dropout | dropout | 0.1 |
dropatt | dropout after softmax in the attention | 0.0 |
lr | base learning rate | 0.01 |
min_lr_ratio | minimum ratio learning rate (for cosine decay) | 0.1 |
max_step | number of training steps | 40,000 |
warmup_step | number of learning rate warmup steps | 1,000 |
batch_size | training batch size | 256 |
tgt_len | number of tokens to predict during training | 192 |
mem_len | number of tokens cached from previous iterations during training | 192 |
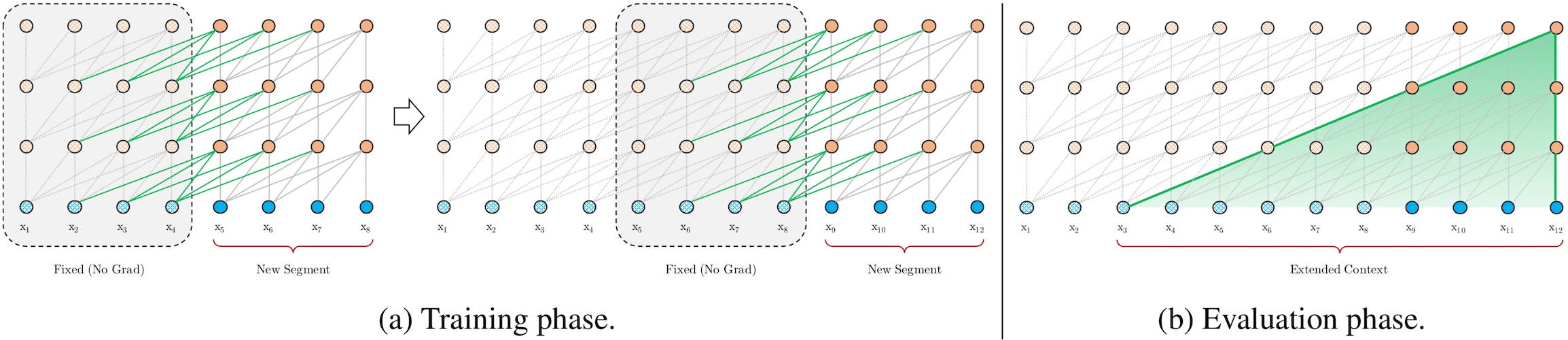
The Transformer-XL model addresses the limitations of vanilla transformer-based language models, which are only able to use relatively short context, bounded by the segment length. The Transformer-XL introduces a recurrence mechanism, which is able to use a cached hidden state from previous segments. During training, the context consists of a concatenation of the current segment's hidden state and cached states from previous iterations. Gradients are backpropagated only through the current segment, although the model is able to take advantage of the extra information stored in the cache and therefore is able to model long-term dependencies.
An illustration of the recurrence mechanism taken from the Transformer-XL
paper is shown below.
Default configuration
The following features were implemented in this model:
- general
- single-node, Horovod multi-GPU training
- training and inference with mixed precision using Tensor Cores
- automatic mixed precision training (AMP)
- model
- 16-layer base Transformer-XL model with hidden size 512, 8 attention heads, each head with hidden size 64
- the model trained on WikiText-103 dataset, using word-level vocabulary and adaptive softmax
- embedding weights are tied with weights in the classifier
- training
- training with LAMB optimizer, the implementation of the optimizer uses XLA, which enables the fusion of elementwise operations and accelerates the training
- support for training with a gradient accumulation
- base model:
- linear learning rate warmup for 1,000 iterations, followed by the cosine learning rate schedule, the initial learning rate is set to 0.0, and the final learning rate is set to 0.001 (min_lr_ratio * base_lr)
- training for 40,000 steps, using a batch size of 256
- inference
- support for single-GPU inference
- each token is using the same size of the context from previous time steps.
- base model:
- target length is set to 64, length of memory is set to 640
- positional embeddings are clamped after 400 time steps
Feature support matrix
The following features are supported by this model:
| Feature | Transformer-XL |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Horovod Multi-GPU (NCCL) | Yes |
| LAMB | Yes |
Features
TF-AMP - a tool that enables Tensor Core-accelerated training. Refer to the Enabling mixed precision section for more details.
Horovod - Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Multi-GPU training with Horovod - our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
LAMB - stands for Layerwise Adaptive Moments Based optimizer, is a large batch optimization technique that helps accelerate training of deep neural networks using large minibatches.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta and Turing GPUs automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
To enable mixed precision, you can simply add the values to the environmental variables inside your training script:
-
Enable TF-AMP graph rewrite:
os.environ["TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE"] = "1" -
Enable Automated Mixed Precision:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.