This implementation of Transformer model architecture is based on the optimized implementation in Fairseq NLP toolkit.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark the training performance on a specific batch size, run train.py training script. Performance in tokens/s will be printed to standard output every N iterations, specified by the --log-interval option. Additionally performance and loss values will be logged by dllogger to the file specified in --stat-file option. Every line in the output file will be a valid JSON file prepended with DLLL prefix.
Inference performance benchmark
To benchmark the inference performance on a specific batch size, run following command to start the benchmark
for i in {1..10}; do sacrebleu -t wmt14/full -l en-de --echo src; done | python inference.py --buffer-size 5000 --path /path/to/your/checkpoint.pt --max-tokens 10240 --fuse-dropout-add --remove-bpe --bpe-codes /data/code --fp16 > /dev/null
Results will be printed to stderr.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Following the spirit of the paper A Call for Clarity in Reporting BLEU Scores we decided to change evaluation metric implemented in fairseq to SacreBleu score. We have calculated that the new metric has almost linear relationship with the old one. We run linear regression on nearly 2000 checkpoints to discover that the SacreBleu score almost perfectly follows the formula: newScore = 0.978 * oldScore - 0.05.
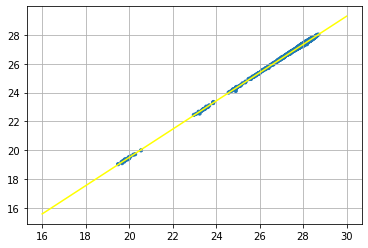
Figure 2. Linear relationship between old and new BLEU metric.
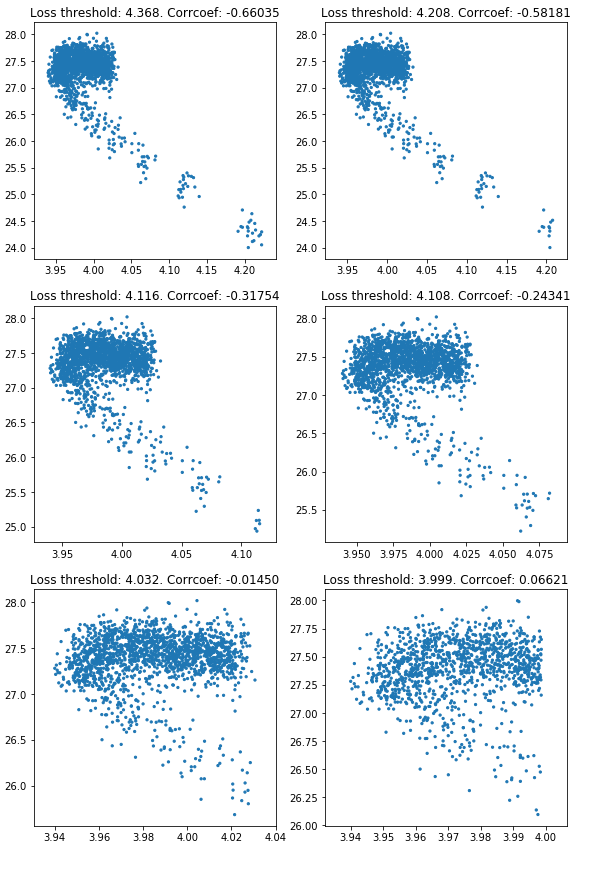
Figure 3. Validation loss vs BLEU score. Plots are trimmed to certain validation loss threshold.
Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
Our results were obtained by running the run_DGXA100_AMP_8GPU.sh and run_DGXA100_TF32_8GPU.sh training scripts in the pytorch-22.06-py3 NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs. We report average accuracy over 6 runs. We consider a model trained when it reaches minimal validation loss. Time to train contains only training time without validation. Depending on a configuration and frequency of validation it can take up to additional minute per epoch.
| GPUs | Batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 10240 | 27.92 | 27.76 | 2.74 hours | 2.64 hours | x1.04 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the run_DGX1_AMP_8GPU.sh and run_DGX1_FP32_8GPU.sh training scripts in the pytorch-22.06-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs. We report average accuracy over 6 runs. We consider a model trained when it reaches minimal validation loss. Time to train contains only training time without validation. Depending on a configuration and frequency of validation it can take up to additional minute per epoch. Using mixed precision we could fit a larger batch size in the memory, further speeding up the training.
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 5120/2560 | 27.66 | 27.82 | 11.8 hours | 4.5 hours | x2.62 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 40GB)
Our results were obtained by running the run_DGXA100_AMP_8GPU.sh and run_DGXA100_TF32_8GPU.sh training scripts in the pytorch-22.06-py3 NGC container on NVIDIA DGX A100 (8x A100 40GB) GPUs. Performance numbers (in tokens per second) were averaged over an entire training epoch.
| GPUs | Batch size / GPU | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 8 | 10240 | 347936 | 551599 | x1.59 | 6.81 | 6.72 |
| 4 | 10240 | 179245 | 286081 | x1.60 | 3.51 | 3.49 |
| 1 | 10240 | 51057 | 82059 | x1.60 | 1 | 1 |
To achieve these same results, follow the steps in the Quick Start Guide.
Training stability test
The following plot shows average validation loss curves for different configs. We can see that training with AMP O2 converges slightly slower that FP32 and TF32 training. In order to mitigate this, you can use option --amp-level O1 at the cost of 20% performance drop compared to the default AMP setting.
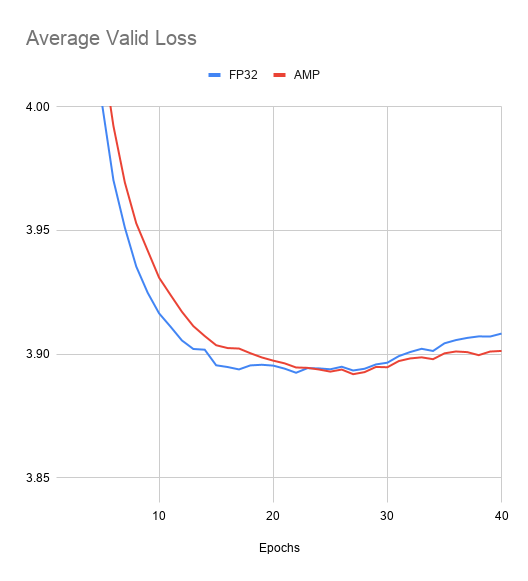
Figure 4. Validation loss curves
Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the run_DGX1_AMP_8GPU.sh and run_DGX1_FP32_8GPU.sh training scripts in the pytorch-22.06-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs. Performance numbers (in tokens per second) were averaged over an entire training epoch. Using mixed precision we could fit a larger batch size in the memory, further speeding up the training.
| GPUs | Batch size / GPU | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 8 | 5120/2560 | 59316 | 214656 | x3.62 | 6.79 | 6.52 |
| 4 | 5120/2560 | 30204 | 109726 | x3.63 | 3.46 | 3.33 |
| 1 | 5120/2560 | 8742 | 32942 | x3.77 | 1 | 1 |
To achieve these same results, follow the steps in the Quick Start Guide.
Training performance: NVIDIA DGX-2 (16x V100 32GB)
Our results were obtained by running the run_DGX1_AMP_8GPU.sh and run_DGX1_FP32_8GPU.sh training scripts setting number of GPUs to 16 in the pytorch-22.06-py3 NGC container on NVIDIA DGX-2 with (16x V100 32GB) GPUs. Performance numbers (in tokens per second) were averaged over an entire training epoch. Using mixed precision we could fit a larger batch size in the memory, further speeding up the training.
| GPUs | Batch size / GPU | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 16 | 10240/5120 | 136253 | 517227 | x3.80 | 13.87 | 12.96 |
| 8 | 10240/5120 | 68929 | 267815 | x3.89 | 7.01 | 6.71 |
| 4 | 10240/5120 | 35216 | 137703 | x3.91 | 3.58 | 3.45 |
| 1 | 10240/5120 | 9827 | 39911 | x4.06 | 1 | 1 |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance results
Our implementation of the Transformer has dynamic batching algorithm, which batches sentences together in such a way that there are no more than N tokens in each batch or no more than M sentences in each batch. In this benchmark we use the first option in order to get the most stable results.
Inference performance: NVIDIA DGX A100 (1x A100 40GB)
Our results were obtained by running the inference.py inferencing benchmarking script in the pytorch-22.06-py3 NGC container on NVIDIA DGX A100 (1x A100 40GB) GPU.
| Precision | Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|---|
| TF32 | 10240 | 7105 | 1.22s | 1.67s | 1.67s | 1.67s |
| FP16 | 10240 | 7988 | 1.09s | 1.73s | 1.73s | 1.73s |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
Our results were obtained by running the inference.py inferencing benchmarking script in the pytorch-22.06-py3 NGC container on NVIDIA DGX-1 with (1x V100 16GB) GPU.
| Precision | Batch size | Throughput Avg | Latency Avg | Latency 90% | Latency 95% | Latency 99% |
|---|---|---|---|---|---|---|
| FP32 | 10240 | 3461 | 2.51s | 3.19 s | 3.19s | 3.19s |
| FP16 | 10240 | 5983 | 1.45s | 2.03 s | 2.03s | 2.03s |
To achieve these same results, follow the steps in the Quick Start Guide.