With a ResNet-50 backbone and a number of architectural modifications, this version provides better accuracy and performance.
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA's latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
The training benchmark was run in various scenarios on A100 80GB and V100 16G GPUs. The benchmark does not require a checkpoint from a fully trained model.
To benchmark training, run:
torchrun --nproc_per_node={NGPU} \
main.py --batch-size {bs} \
--mode benchmark-training \
--benchmark-warmup 100 \
--benchmark-iterations 200 \
{AMP} \
--data {data}
Where the {NGPU} selects number of GPUs used in benchmark, the {bs} is the desired
batch size, the {AMP} is set to --amp if you want to benchmark training with
Tensor Cores, and the {data} is the location of the COCO 2017 dataset.
--benchmark-warmup is specified to omit the first iteration of the first epoch.
--benchmark-iterations is a number of iterations used to measure performance.
Inference performance benchmark
Inference benchmark was run on 1x A100 80GB GPU and 1x V100 16G GPU. To benchmark inference, run:
python main.py --eval-batch-size {bs} \
--mode benchmark-inference \
--benchmark-warmup 100 \
--benchmark-iterations 200 \
{AMP} \
--data {data}
Where the {bs} is the desired batch size, the {AMP} is set to --amp if you want to benchmark inference with Tensor Cores, and the {data} is the location of the COCO 2017 dataset.
--benchmark-warmup is specified to omit the first iterations of the first epoch. --benchmark-iterations is a number of iterations used to measure performance.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the ./examples/SSD300_A100_{FP16,TF32}_{1,4,8}GPU.sh
script in the pytorch-22.10-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs.
| GPUs | Batch size / GPU | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 64 | 0.271 | 0.272 | 03:19:59 | 03:18:35 | 100% |
| 4 | 64 | 0.270 | 0.270 | 00:51:22 | 00:51:31 | 99% |
| 8 | 64 | 0.270 | 0.269 | 00:26:10 | 00:26:10 | 99% |
| 1 | 128 | 0.274 | 0.271 | 03:03:56 | 03:03:50 | 100% |
| 4 | 128 | 0.272 | 0.270 | 00:46:51 | 00:47:01 | 99% |
| 8 | 128 | 0.267 | 0.267 | 00:23:44 | 00:23:46 | 99% |
| 1 | 256 | 0.272 | 0.272 | 02:56:37 | 02:56:44 | 99% |
| 4 | 256 | 0.271 | 0.267 | 00:45:05 | 00:45:07 | 99% |
| 8 | 256 | 0.260 | 0.258 | 00:22:49 | 00:22:56 | 100% |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the ./examples/SSD300_FP{16,32}_{1,4,8}GPU.sh
script in the pytorch-22.10-py3 NGC container on NVIDIA DGX-1 with 8x
V100 16GB GPUs.
| GPUs | Batch size / GPU | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|
| 1 | 32 | 0.269 | 0.271 | 20:04:48 | 07:25:27 | 270% |
| 4 | 32 | 0.270 | 0.269 | 05:08:56 | 01:58:41 | 260% |
| 8 | 32 | 0.271 | 0.269 | 02:35:00 | 01:00:27 | 256% |
| 1 | 64 | <N/A> | 0.272 | <N/A> | 06:47:58 | <N/A> |
| 4 | 64 | <N/A> | 0.270 | <N/A> | 01:46:34 | <N/A> |
| 8 | 64 | <N/A> | 0.269 | <N/A> | 00:53:52 | <N/A> |
Due to smaller size, mixed precision models can be trained with bigger batches. In such cases mixed precision speedup is calculated versus FP32 training with maximum batch size for that precision
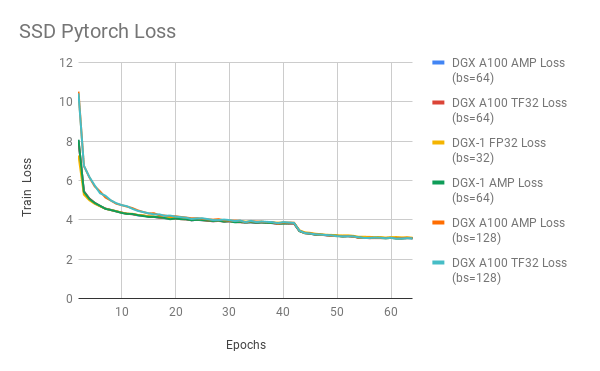
Training loss plot
Here are example graphs of FP32, TF32 and AMP training on 8 GPU configuration:
Training stability test
The SSD300 v1.1 model was trained for 65 epochs, starting
from 15 different initial random seeds. The training was performed in the pytorch-22.10-py3 NGC container on
NVIDIA DGX A100 8x A100 80GB GPUs with batch size per GPU = 128.
After training, the models were evaluated on the test dataset. The following
table summarizes the final mAP on the test set.
| Precision | Average mAP | Standard deviation | Minimum | Maximum | Median |
|---|---|---|---|---|---|
| AMP | 0.2679503039 | 0.001360494012 | 0.26201 | 0.27013 | 0.26529 |
| TF32 | 0.2670691823 | 0.001639394102 | 0.26181 | 0.27274 | 0.26492 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the main.py script with the --mode benchmark-training flag in the pytorch-22.10-py3 NGC container on NVIDIA
DGX A100 (8x A100 80GB) GPUs. Performance numbers (in items/images per second)
were averaged over an entire training epoch.
| GPUs | Batch size / GPU | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 64 | 364.27 | 662.91 | 181% | 100% | 100% |
| 4 | 64 | 1432.73 | 2581.24 | 180% | 393% | 389% |
| 8 | 64 | 2838.76 | 5252.84 | 185% | 779% | 792% |
| 1 | 128 | 377.18 | 724.41 | 192% | 100% | 100% |
| 4 | 128 | 1493.13 | 2885.55 | 193% | 395% | 398% |
| 8 | 128 | 2967.23 | 5733.98 | 193% | 786% | 791% |
To achieve these same results, follow the Quick Start Guide outlined above.
Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the main.py script with the --mode benchmark-training flag in the pytorch-22.10-py3 NGC container on NVIDIA
DGX-1 with 8x V100 16GB GPUs. Performance numbers (in items/images per second)
were averaged over an entire training epoch.
| GPUs | Batch size / GPU | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 32 | 107.22 | 296.80 | 276% | 100% | 100% |
| 4 | 32 | 419.54 | 1115.59 | 265% | 391% | 375% |
| 8 | 32 | 840.35 | 2153.96 | 256% | 783% | 725% |
| 1 | 64 | <N/A> | 322.81 | <N/A> | <N/A> | 100% |
| 4 | 64 | <N/A> | 1238.27 | <N/A> | <N/A> | 383% |
| 8 | 64 | <N/A> | 2520.50 | <N/A> | <N/A> | 780% |
Due to smaller size, mixed precision models can be trained with bigger batches. In such cases mixed precision speedup is calculated versus FP32 training with maximum batch size for that precision
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 80GB)
Our results were obtained by running the main.py script with --mode benchmark-inference flag in the pytorch-22.10-py3 NGC container on NVIDIA
DGX A100 (1x A100 80GB) GPU.
| Batch size | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|
| 1 | 158.83 | 142.67 | 89% | 100% | 100% |
| 2 | 308.31 | 261.21 | 84% | 194% | 183% |
| 4 | 481.69 | 454.95 | 94% | 303% | 318% |
| 8 | 597.72 | 742.05 | 124% | 376% | 520% |
| 16 | 590.44 | 887.01 | 150% | 371% | 621% |
| 32 | 708.97 | 970.27 | 136% | 446% | 680% |
| 64 | 798.16 | 1057.51 | 132% | 502% | 741% |
To achieve these same results, follow the Quick Start Guide outlined above.
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
Our results were obtained by running the main.py script with --mode benchmark-inference flag in the pytorch-22.10-py3 NGC container on NVIDIA
DGX-1 with (1x V100 16GB) GPU.
| Batch size | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|
| 1 | 93.21 | 84.59 | 90% | 100% | 100% |
| 2 | 148.61 | 165.30 | 111% | 159% | 195% |
| 4 | 206.82 | 304.77 | 147% | 221% | 360% |
| 8 | 242.55 | 447.25 | 184% | 260% | 528% |
| 16 | 292.44 | 541.05 | 185% | 313% | 639% |
| 32 | 311.61 | 605.30 | 194% | 334% | 715% |
To achieve these same results, follow the Quick Start Guide outlined above.