With a ResNet-50 backbone and a number of architectural modifications, this version provides better accuracy and performance.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
The SSD300 v1.1 model is based on the SSD: Single Shot MultiBox Detector paper, which describes SSD as "a method for detecting objects in images using a single deep neural network". The input size is fixed to 300x300.
The main difference between this model and the one described in the paper is in the backbone. Specifically, the VGG model is obsolete and is replaced by the ResNet-50 model.
From the Speed/accuracy trade-offs for modern convolutional object detectors paper, the following enhancements were made to the backbone:
- The conv5_x, avgpool, fc and softmax layers were removed from the original classification model.
- All strides in conv4_x are set to 1x1.
Detector heads are similar to the ones referenced in the paper, however, they are enhanced by additional BatchNorm layers after each convolution.
Additionally, we removed weight decay on every bias parameter and all the BatchNorm layer parameters as described in the Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes paper.
Training of SSD requires computational costly augmentations. To fully utilize GPUs during training we are using the NVIDIA DALI library to accelerate data preparation pipelines.
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 2x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
Despite the changes described in the previous section, the overall architecture, as described in the following diagram, has not changed.
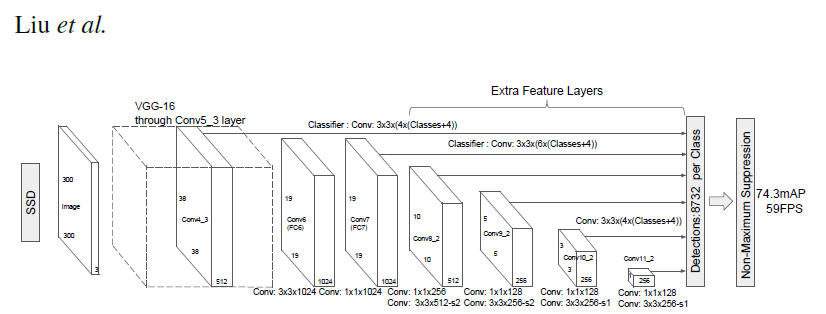
Figure 1. The architecture of a Single Shot MultiBox Detector model. Image has been taken from the Single Shot MultiBox Detector paper.
The backbone is followed by 5 additional convolutional layers. In addition to the convolutional layers, we attached 6 detection heads:
- The first detection head is attached to the last conv4_x layer.
- The other five detection heads are attached to the corresponding 5 additional layers.
Default configuration
We trained the model for 65 epochs with the following setup:
- SGD with momentum (0.9)
- Learning rate = 2.6e-3 * number of GPUs * (batch_size / 32)
- Learning rate decay – multiply by 0.1 before 43 and 54 epochs
- We use linear warmup of the learning rate during the first epoch.
For more information, see the Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour paper.
To enable warmup provide argument the --warmup 300
- Weight decay: * 0 for BatchNorms and biases * 5e-4 for other layers
Note: The learning rate is automatically scaled (in other words, multiplied by the number of GPUs and multiplied by the batch size divided by 32).
Feature support matrix
The following features are supported by this model.
| Feature | SSD300 v1.1 PyTorch |
|---|---|
| AMP | Yes |
| APEX DDP | Yes |
| NVIDIA DALI | Yes |
Features
AMP is an abbreviation used for automatic mixed precision training.
DDP stands for DistributedDataParallel and is used for multi-GPU training.
NVIDIA DALI - DALI is a library accelerating data preparation pipeline. To accelerate your input pipeline, you only need to define your data loader with the DALI library. For details, see example sources in this repo or see the DALI documentation
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- PyTorch AMP, see the PyTorch Automatic Mixed Precision package.
Enabling mixed precision
Mixed precision is enabled in PyTorch by using the Automatic Mixed Precision (AMP) autocast torch.cuda.amp.autocast which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a gradient scaling step must be included.
For an in-depth walk through on AMP, check out sample usage here.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
backbone : a part of a many object detection architectures, usually pre-trained for a different, simpler task, like classification.
input pipeline : set of operations performed for every item in input data before feeding the neural network. Especially for object detection task, the input pipeline can be complex and computationally significant. For that reason, solutions like NVIDIA DALI emerged.
object detection : a subset of Computer Vision problem. The task of object detection is to localize possibly multiple objects on the image and classify them. The difference between Object Detection, Image Classification, and Localization are clearly explained in the video published as a part of the C4W3L01 course.
SSD (Single Shot MultiBox Detector) : a name for the detection model described in a paper authored by Liu at al.
ResNet (ResNet-50) : a name for the classification model described in a paper authored by He et al. In this repo, it is used as a backbone for SSD.