A Graph Neural Network using a variant of self-attention for 3D points and graphs processing.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
The SE(3)-Transformer is a Graph Neural Network using a variant of self-attention for 3D points and graphs processing. This model is equivariant under continuous 3D roto-translations, meaning that when the inputs (graphs or sets of points) rotate in 3D space (or more generally experience a proper rigid transformation), the model outputs either stay invariant or transform with the input. A mathematical guarantee of equivariance is important to ensure stable and predictable performance in the presence of nuisance transformations of the data input and when the problem has some inherent symmetries we want to exploit.
The model is based on the following publications:
- SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks (NeurIPS 2020) by Fabian B. Fuchs, Daniel E. Worrall, et al.
- Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds by Nathaniel Thomas, Tess Smidt, et al.
A follow-up paper explains how this model can be used iteratively, for example, to predict or refine protein structures:
- Iterative SE(3)-Transformers by Fabian B. Fuchs, Daniel E. Worrall, et al.
Just like the official implementation, this implementation uses PyTorch and the Deep Graph Library (DGL).
The main differences between this implementation of SE(3)-Transformers and the official one are the following:
- Training and inference support for multiple GPUs
- Training and inference support for Mixed Precision
- The QM9 dataset from DGL is used and automatically downloaded
- Significantly increased throughput
- Significantly reduced memory consumption
- The use of layer normalization in the fully connected radial profile layers is an option (
--use_layer_norm), off by default - The use of equivariant normalization between attention layers is an option (
--norm), off by default - The spherical harmonics and Clebsch–Gordan coefficients, used to compute bases matrices, are computed with the e3nn library
This model enables you to predict quantum chemical properties of small organic molecules in the QM9 dataset. In this case, the exploited symmetry is that these properties do not depend on the orientation or position of the molecules in space.
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta, NVIDIA Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 1.5x faster than training without Tensor Cores while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
The model consists of stacked layers of equivariant graph self-attention and equivariant normalization. Lastly, a Tensor Field Network convolution is applied to obtain invariant features. Graph pooling (mean or max over the nodes) is applied to these features, and the result is fed to a final MLP to get scalar predictions.
In this setup, the model is a graph-to-scalar network. The pooling can be removed to obtain a graph-to-graph network, and the final TFN can be modified to output features of any type (invariant scalars, 3D vectors, ...).
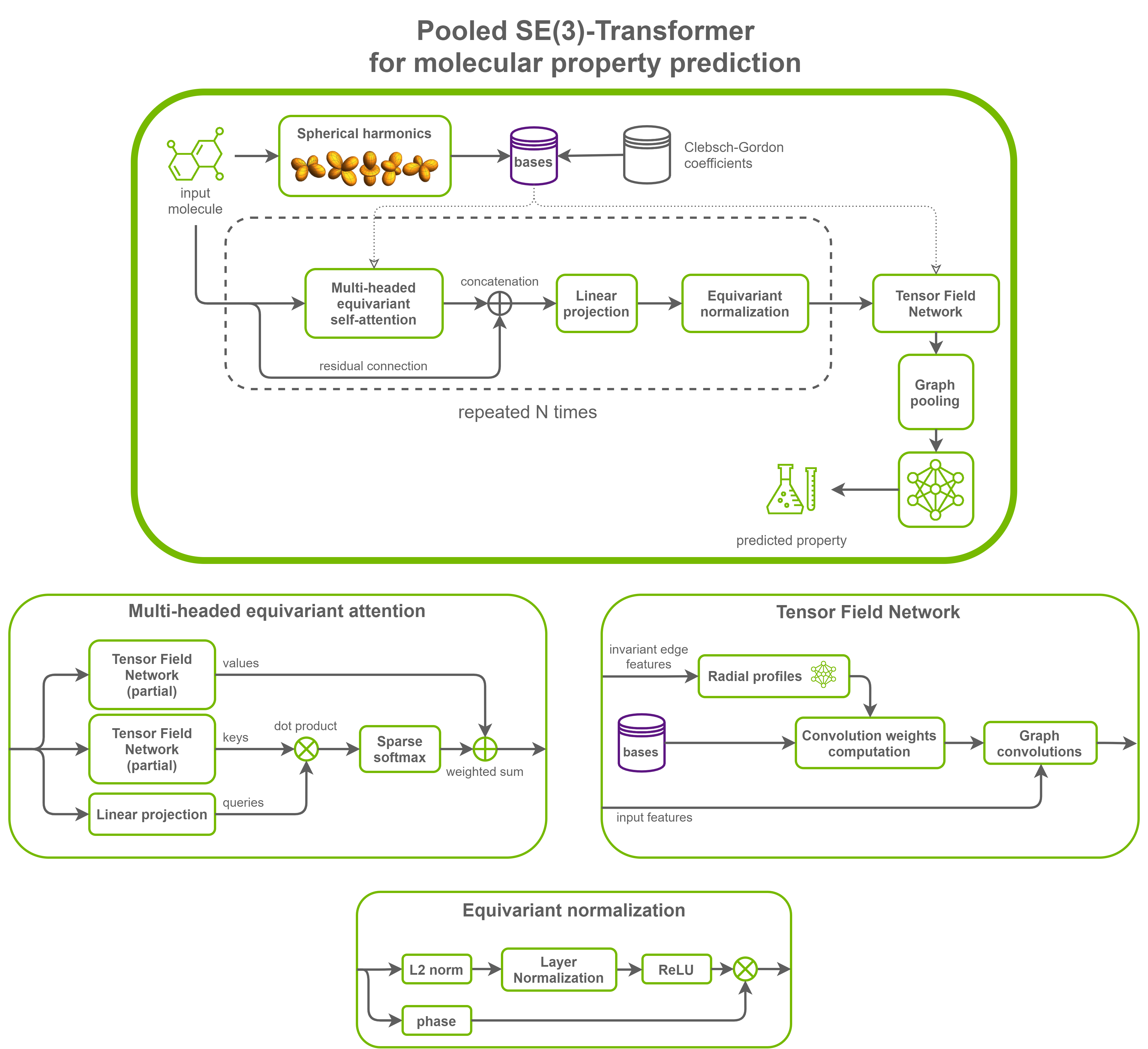
Default configuration
SE(3)-Transformers introduce a self-attention layer for graphs that is equivariant to 3D roto-translations. It achieves this by leveraging Tensor Field Networks to build attention weights that are invariant and attention values that are equivariant. Combining the equivariant values with the invariant weights gives rise to an equivariant output. This output is normalized while preserving equivariance thanks to equivariant normalization layers operating on feature norms.
The following features were implemented in this model:
- Support for edge features of any degree (1D, 3D, 5D, ...), whereas the official implementation only supports scalar invariant edge features (degree 0). Edge features with a degree greater than one are concatenated to node features of the same degree. This is required in order to reproduce published results on point cloud processing.
- Data-parallel multi-GPU training (DDP)
- Mixed precision training (autocast, gradient scaling)
- Gradient accumulation
- Model checkpointing
The following performance optimizations were implemented in this model:
General optimizations
- The option is provided to precompute bases at the beginning of the training instead of computing them at the beginning of each forward pass (
--precompute_bases) - The bases computation is just-in-time (JIT) compiled with
torch.jit.script - The Clebsch-Gordon coefficients are cached in RAM
Tensor Field Network optimizations
-
The last layer of each radial profile network does not add any bias in order to avoid large broadcasting operations
-
The layout (order of dimensions) of the bases tensors is optimized to avoid copies to contiguous memory in the downstream TFN layers
-
When Tensor Cores are available, and the output feature dimension of computed bases is odd, then it is padded with zeros to make more effective use of Tensor Cores (AMP and TF32 precisions)
-
Multiple levels of fusion for TFN convolutions (and radial profiles) are provided and automatically used when conditions are met
-
A low-memory mode is provided that will trade throughput for less memory use (
--low_memory). Overview of memory savings over the official implementation (batch size 100), depending on the precision and the low memory mode:FP32 AMP --low_memory false(default)4.7x 7.1x --low_memory true29.4x 43.6x
Self-attention optimizations
- Attention keys and values are computed by a single partial TFN graph convolution in each attention layer instead of two
- Graph operations for different output degrees may be fused together if conditions are met
Normalization optimizations
- The equivariant normalization layer is optimized from multiple layer normalizations to a group normalization on fused norms when certain conditions are met
Competitive training results and analysis are provided for the following hyperparameters (identical to the ones in the original publication):
- Number of layers: 7
- Number of degrees: 4
- Number of channels: 32
- Number of attention heads: 8
- Channels division: 2
- Use of equivariant normalization: true
- Use of layer normalization: true
- Pooling: max
Feature support matrix
This model supports the following features::
| Feature | SE(3)-Transformer |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Distributed data parallel (DDP) | Yes |
Features
Distributed data parallel (DDP)
DistributedDataParallel (DDP) implements data parallelism at the module level that can run across multiple GPUs or machines.
Automatic Mixed Precision (AMP)
This implementation uses the native PyTorch AMP implementation of mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just a few lines of code. A detailed explanation of mixed precision can be found in the next section.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in NVIDIA Volta, and following with both the NVIDIA Turing and NVIDIA Ampere Architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
AMP enables mixed precision training on NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere GPU architectures automatically. The PyTorch framework code makes all necessary model changes internally.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
- APEX tools for mixed precision training, refer to the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
Mixed precision is enabled in PyTorch by using the native Automatic Mixed Precision package, which casts variables to half-precision upon retrieval while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In PyTorch, loss scaling can be applied automatically using a GradScaler.
Automatic Mixed Precision makes all the adjustments internally in PyTorch, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running PyTorch models.
To enable mixed precision, you can simply use the --amp flag when running the training or inference scripts.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models that require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Degree (type)
In the model, every feature (input, output and hidden) transforms in an equivariant way in relation to the input graph. When we define a feature, we need to choose, in addition to the number of channels, which transformation rule it obeys.
The degree or type of a feature is a positive integer that describes how this feature transforms when the input rotates in 3D.
This is related to irreducible representations of different rotation orders.
The degree of a feature determines its dimensionality. A type-d feature has a dimensionality of 2d+1.
Some common examples include:
- Degree 0: 1D scalars invariant to rotation
- Degree 1: 3D vectors that rotate according to 3D rotation matrices
- Degree 2: 5D vectors that rotate according to 5D Wigner-D matrices. These can represent symmetric traceless 3x3 matrices.
Fiber
A fiber can be viewed as a representation of a set of features of different types or degrees (positive integers), where each feature type transforms according to its rule.
In this repository, a fiber can be seen as a dictionary with degrees as keys and numbers of channels as values.
Multiplicity
The multiplicity of a feature of a given type is the number of channels of this feature.
Tensor Field Network
A Tensor Field Network is a kind of equivariant graph convolution that can combine features of different degrees and produce new ones while preserving equivariance thanks to tensor products.
Equivariance
Equivariance is a property of a function of model stating that applying a symmetry transformation to the input and then computing the function produces the same result as computing the function and then applying the transformation to the output.
In the case of SE(3)-Transformer, the symmetry group is the group of continuous roto-translations (SE(3)).