An optimized, robust and self-adapting framework for U-Net based medical image segmentation
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
The nnU-Net ("no-new-Net") refers to a robust and self-adapting framework for U-Net based medical image segmentation. This repository contains a nnU-Net implementation as described in the paper: nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation.
The differences between this nnU-net and original model are:
- Dynamic selection of patch size is not supported, and it has to be set in
data_preprocessing/configs.pyfile. - Cascaded U-Net is not supported.
- The following data augmentations are not used: rotation, simulation of low resolution, gamma augmentation.
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 2x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
We developed the model using PyTorch Lightning, a new easy-to-use framework that ensures code readability and reproducibility without the boilerplate.
Model architecture
The nnU-Net allows the training of two types of networks: 2D U-Net and 3D U-Net to perform semantic segmentation of 3D images, with high accuracy and performance.
The following figure shows the architecture of the 3D U-Net model and its different components. U-Net is composed of a contractive and an expanding path, that aims at building a bottleneck in its centremost part through a combination of convolution, instance norm, and leaky ReLU operations. After this bottleneck, the image is reconstructed through a combination of convolutions and upsampling. Skip connections are added with the goal of helping the backward flow of gradients to improve the training.
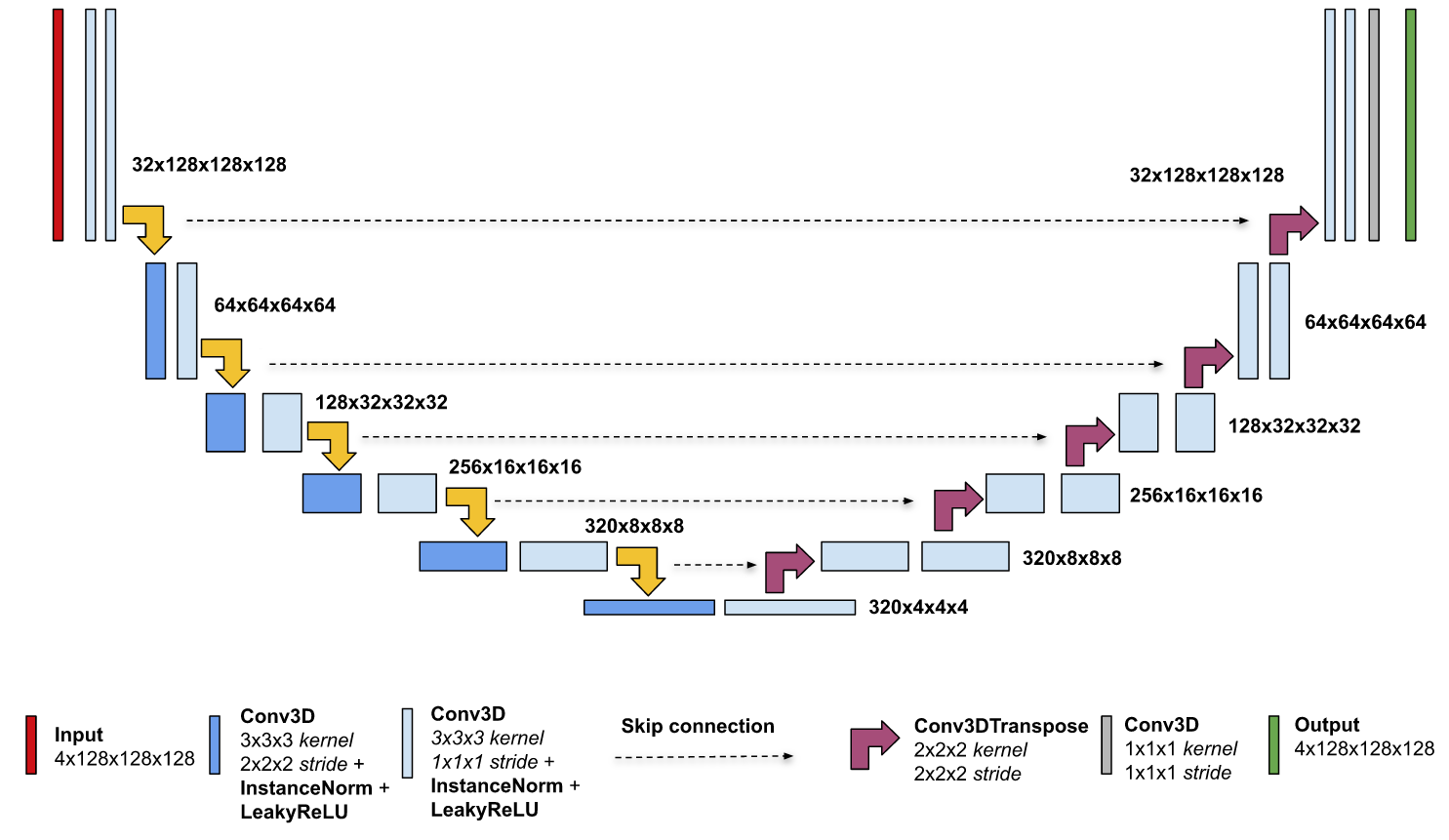
Figure 1: The 3D U-Net architecture
Default configuration
All convolution blocks in U-Net in both encoder and decoder are using two convolution layers followed by instance normalization and a leaky ReLU nonlinearity. For downsampling, we are using stride convolution whereas transposed convolution is used for upsampling.
All models were trained with an Adam optimizer. For loss function we use the average of cross-entropy and dice coefficient.
Early stopping is triggered if the validation dice score wasn't improved during the last 100 epochs.
Used data augmentation: crop with oversampling the foreground class, mirroring, zoom, Gaussian noise, Gaussian blur, brightness, and contrast.
Feature support matrix
The following features are supported by this model:
| Feature | nnUNet |
|---|---|
| DALI | Yes |
| Automatic mixed precision (AMP) | Yes |
| Distributed data-parallel (DDP) | Yes |
Features
DALI
NVIDIA DALI - DALI is a library-accelerating data preparation pipeline. To speed up your input pipeline, you only need to define your data loader with the DALI library. For details, see example sources in this repository or see the DALI documentation
Automatic Mixed Precision (AMP)
This implementation uses native PyTorch AMP implementation of mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying a few lines of code.
DistributedDataParallel (DDP)
The model uses PyTorch Lightning implementation of distributed data parallelism at the module level which can run across multiple machines.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to keep as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x speedup on the most intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- APEX tools for mixed precision training, see the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
For training and inference, mixed precision can be enabled by adding the --amp flag. Mixed precision is using native PyTorch implementation.
TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Test time augmentation
Test time augmentation is an inference technique that averages predictions from augmented images with its prediction. As a result, predictions are more accurate, but with the cost of a slower inference process. For nnU-Net, we use all possible flip combinations for image augmenting. Test time augmentation can be enabled by adding the --tta flag.