The NCF model focuses on providing recommendations. This is a modified implementation with improved overfitting and better accuracy.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
The Neural Collaborative Filtering (NCF) model is a neural network that provides collaborative filtering based on implicit feedback. Specifically, it provides product recommendations based on user and item interactions. The training data for this model should contain a sequence of (user ID, item ID) pairs indicating that the specified user has interacted with an item, for example, by giving a rating or clicking. NCF was first described by Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu and Tat-Seng Chua in the Neural Collaborative Filtering paper.
The implementation in this repository focuses on the NeuMF instantiation of the NCF architecture. We modified it to use Dropout in the fully connected layers. This reduces overfitting and increases the final accuracy. Training the other two instantiations of NCF (GMF and MLP) is not supported.
The original paper evaluates the model on the ml-1m dataset. Conversely, we evaluate on the ml-20m dataset, which provides a more practical production scenario. However, using the ml-1m dataset is also supported.
This model takes advantage of the mixed precision Tensor Cores found on Volta, Turing, and the NVIDIA Ampere GPU architectures demonstrating the reduction in training time possible by leveraging Tensor Cores. In the single GPU configuration, training times can be improved close to 1.6x through the usage of Tensor Cores.
This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
NCF-TF takes in a sequence of (user ID, item ID) pairs as inputs, then feeds them separately into a matrix factorization step (where the embeddings are multiplied) and into a multilayer perceptron (MLP) network.
The outputs of the matrix factorization and the MLP network are then combined and fed into a single dense layer which predicts whether the input user is likely to interact with the input item. The architecture of the MLP network is shown below.
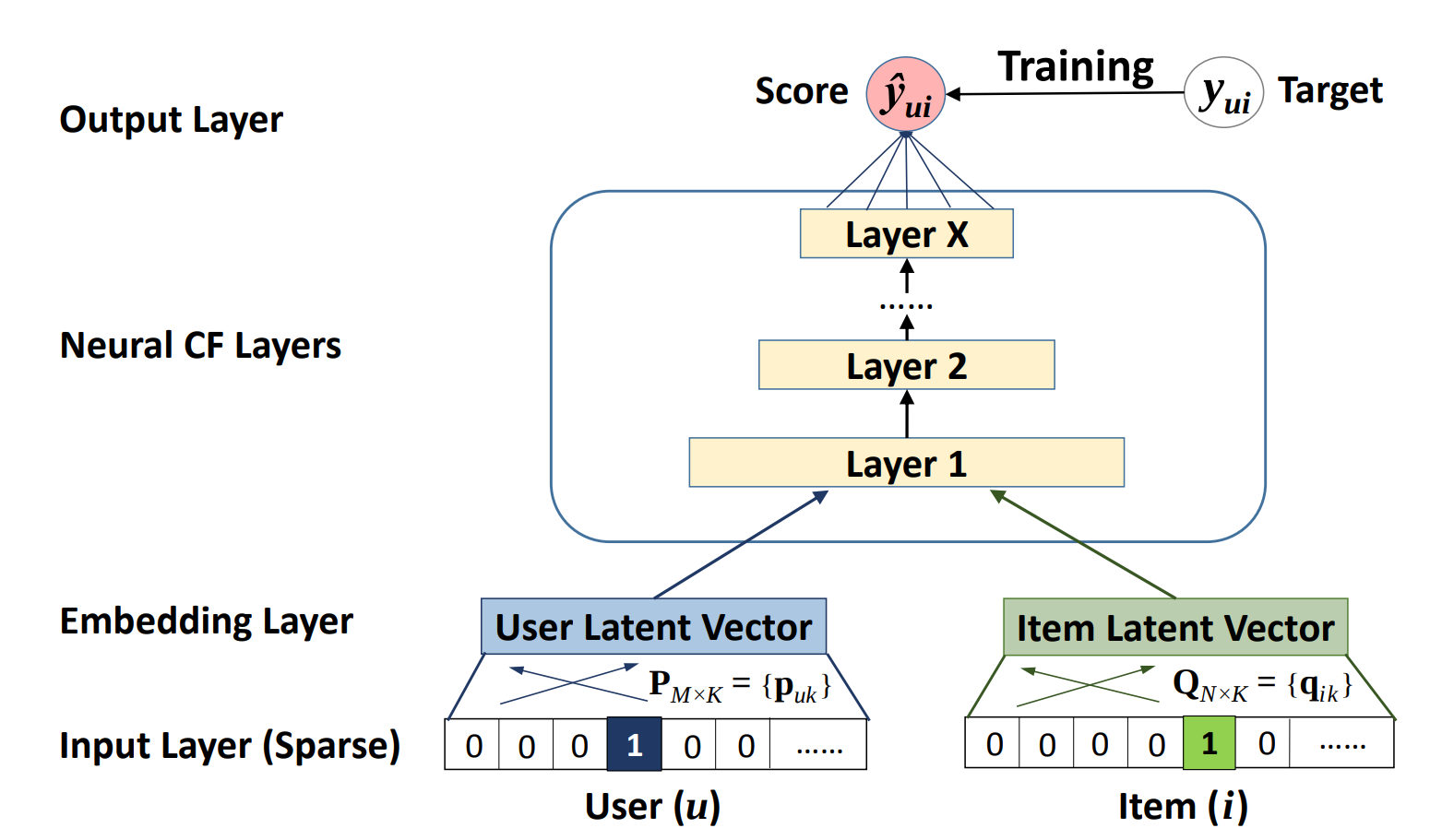
Figure 1. The architecture of a Neural Collaborative Filtering model. Taken from the Neural Collaborative Filtering paper.
Default Configuration
This implementation has the following features:
- model-parallel multi-gpu training with Horovod
- mixed precision training with TF-AMP (TensorFlow-Automatic Mixed Precision), which enables mixed precision training without any changes to the code-base by performing automatic graph rewrites and loss scaling controlled by an environmental variable
- fast negative sample generation and data preprocessing with CuPy
- Before each training epoch, the training data is augmented with randomly generated negatives samples. A "shortcut" is enabled by default where the script does not verify that the randomly generated samples are actually negative samples. We have found that this shortcut has a low impact on model accuracy while considerably improving the speed and memory footprint of the data augmentation stage of training.
- Note: The negative samples generated for the test set are always verified regardless of the shortcut being enabled or not.
Feature support matrix
| Feature | NCF-TF |
|---|---|
| Horovod | Yes |
| Automatic mixed precision (AMP) | Yes |
Features
Horovod
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Multi-GPU training with Horovod
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
Automatic Mixed Precision (AMP)
Computation graphs can be modified by TensorFlow on runtime to support mixed precision training. Detailed explanation of mixed precision can be found in the next section.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta, Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
To enable mixed precision, you can simply add the values to the environmental variables inside your training script:
-
Enable TF-AMP graph rewrite:
os.environ["TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE"] = "1" -
Enable Automated Mixed Precision:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.