The NCF model focuses on providing recommendations. This is a modified implementation with improved overfitting and better accuracy.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
The NCF model focuses on providing recommendations, also known as collaborative filtering with implicit feedback. The training data for this model should contain binary information about whether a user interacted with a specific item. NCF was first described by Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu and Tat-Seng Chua in the Neural Collaborative Filtering paper.
The implementation in this repository focuses on the NeuMF instantiation of the NCF architecture. We modified it to use dropout in the FullyConnected layers. This reduces overfitting and increases the final accuracy. Training the other two instantiations of NCF (GMF and MLP) is not supported.
Contrary to the original paper, we benchmark the model on the larger ML-20m dataset instead of using the smaller ML-1m dataset because we think this is more realistic for production type environments. However, using the ML-1m dataset is also supported.
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 2x faster than training without Tensor Cores while experiencing the benefits of mixed precision training.
Model architecture
This model is based mainly on Embedding and FullyConnected layers. The control flow is divided into two branches:
- Multi Layer Perceptron (MLP) branch, which transforms the input through FullyConnected layers with ReLU activations, and dropout.
- Matrix Factorization (MF) branch, which performs collaborative filtering factorization. Each user and each item has two embedding vectors associated with it -- one for the MLP branch and the other for the MF branch.
The outputs from those branches are concatenated and fed to the final FullyConnected layer with sigmoid activation. This can be interpreted as a probability of a user interacting with a given item.
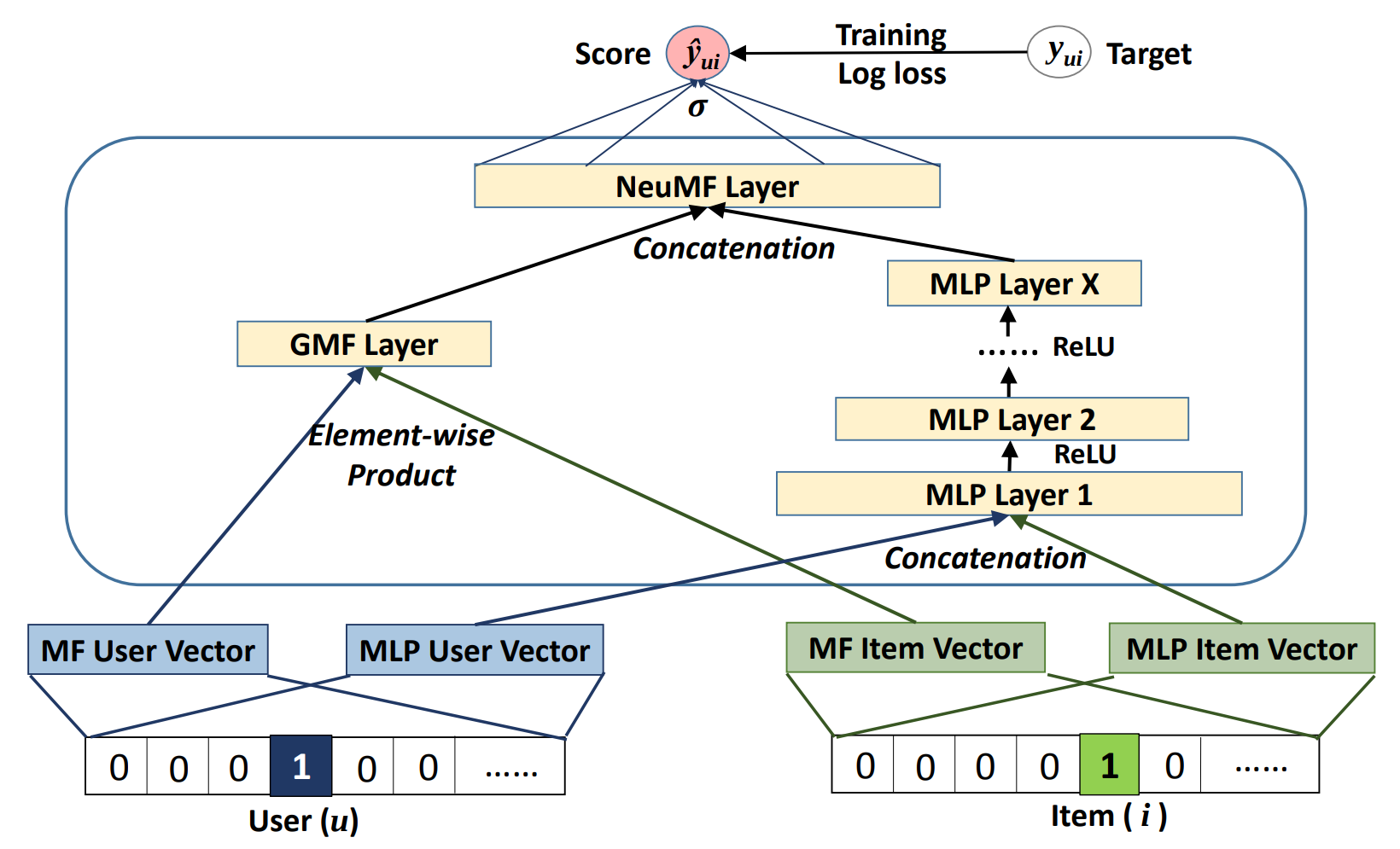
Figure 1. The architecture of a Neural Collaborative Filtering model. Taken from the Neural Collaborative Filtering paper.
Default configuration
The following features were implemented in this model:
- Automatic Mixed Precision (AMP)
- Data-parallel multi-GPU training and evaluation
- Dropout
- Gradient accumulation
The following performance optimizations were implemented in this model:
- FusedAdam optimizer
- Approximate train negative sampling
- Caching all the positive training samples in the device memory
Feature support matrix
This model supports the following features:
| Feature | NCF PyTorch |
|---|---|
| Automatic Mixed Precision (AMP) | Yes |
| Multi-GPU training with Distributed Data Parallel (DDP) | Yes |
| Fused Adam | Yes |
Features
- Automatic Mixed Precision - This implementation of NCF uses AMP to implement mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just three lines of code.
- Multi-GPU training with Distributed Data Parallel - uses Apex's DDP to implement efficient multi-GPU training with NCCL.
- Fused Adam - We use a special implementation of the Adam implementation provided by the Apex package. It fuses some operations for faster weight updates. Since NCF is a relatively lightweight model with a large number of parameters, we've observed significant performance improvements from using FusedAdam.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of tensor cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
- APEX tools for mixed precision training, refer to the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
Using the Automatic Mixed Precision (AMP) package requires two modifications in the source code.
The first one is to initialize the model and the optimizer using the amp.initialize function:
model, optimizer = amp.initialize(model, optimizer, opt_level="O2"
keep_batchnorm_fp32=False, loss_scale='dynamic')
The second one is to use the AMP's loss scaling context manager:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
BYO dataset functionality overview
This section describes how you can train the DeepLearningExamples RecSys models on your own datasets without changing the model or data loader and with similar performance to the one published in each repository. This can be achieved thanks to Dataset Feature Specification, which describes how the dataset, data loader and model interact with each other during training, inference and evaluation. Dataset Feature Specification has a consistent format across all recommendation models in NVIDIA's DeepLearningExamples repository, regardless of dataset file type and the data loader, giving you the flexibility to train RecSys models on your own datasets.
- Dataset Feature Specification
- Data Flow in Recommendation Models in DeepLearning examples
- Example of Dataset Feature Specification
- BYO dataset functionality
- Glossary
Dataset feature specification
Data flow can be described abstractly: Input data consists of a list of rows. Each row has the same number of columns; each column represents a feature. The columns are retrieved from the input files, loaded, aggregated into channels and supplied to the model/training script.
FeatureSpec contains metadata to configure this process and can be divided into three parts:
-
Specification of how data is organized on disk (source_spec). It describes which feature (from feature_spec) is stored in which file and how files are organized on disk.
-
Specification of features (feature_spec). Describes a dictionary of features, where key is feature name and values are features' characteristics such as dtype and other metadata (for example, cardinalities for categorical features)
-
Specification of model's inputs and outputs (channel_spec). Describes a dictionary of model's inputs where keys specify model channel's names and values specify lists of features to be loaded into that channel. Model's channels are groups of data streams to which common model logic is applied, for example categorical/continuous data, user/item ids. Required/available channels depend on the model
The FeatureSpec is a common form of description regardless of underlying dataset format, dataset data loader form and model.
Data flow in NVIDIA Deep Learning Examples recommendation models
The typical data flow is as follows:
- S.0. Original dataset is downloaded to a specific folder.
- S.1. Original dataset is preprocessed into Intermediary Format. For each model, the preprocessing is done differently, using different tools. The Intermediary Format also varies (for example, for NCF implementation in the PyTorch model, the Intermediary Format is Pytorch tensors in *.pt files.)
- S.2. The Preprocessing Step outputs Intermediary Format with dataset split into training and validation/testing parts along with the Dataset Feature Specification yaml file. Metadata in the preprocessing step is automatically calculated.
- S.3. Intermediary Format data together with Dataset Feature Specification are fed into training/evaluation scripts. Data loader reads Intermediary Format and feeds the data into the model according to the description in the Dataset Feature Specification.
- S.4. The model is trained and evaluated
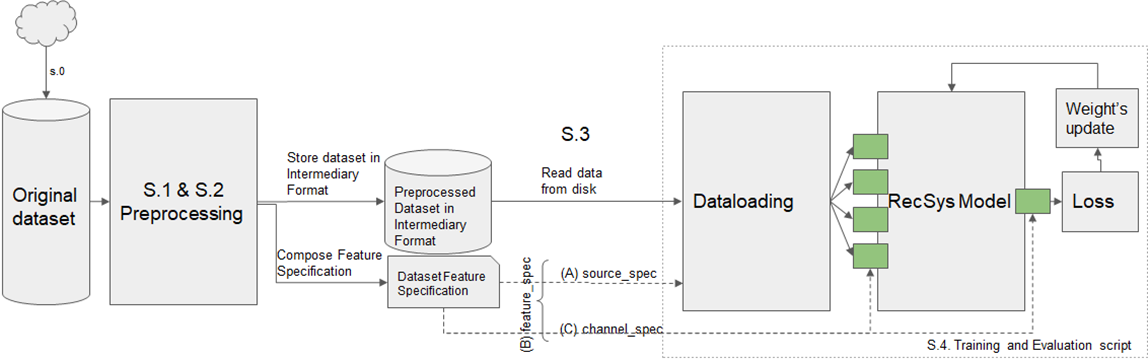
Fig.1. Data flow in Recommender models in NVIDIA Deep Learning Examples repository. Channels of the model are drawn in green.
Example of dataset feature specification
As an example, let's consider a Dataset Feature Specification for a small CSV dataset.
feature_spec:
user_gender:
dtype: torch.int8
cardinality: 3 #M,F,Other
user_age: #treated as numeric value
dtype: torch.int8
user_id:
dtype: torch.int32
cardinality: 2655
item_id:
dtype: torch.int32
cardinality: 856
label:
dtype: torch.float32
source_spec:
train:
- type: csv
features:
- user_gender
- user_age
files:
- train_data_0_0.csv
- train_data_0_1.csv
- type: csv
features:
- user_id
- item_id
- label
files:
- train_data_1.csv
test:
- type: csv
features:
- user_id
- item_id
- label
- user_gender
- user_age
files:
- test_data.csv
channel_spec:
numeric_inputs:
- user_age
categorical_user_inputs:
- user_gender
- user_id
categorical_item_inputs:
- item_id
label_ch:
- label
The data contains five features: (user_gender, user_age, user_id, item_id, label). Their data types and necessary metadata are described in the feature specification section.
In the source mapping section, two mappings are provided: one describes the layout of the training data, the other of the testing data. The layout for training data has been chosen arbitrarily to showcase the flexibility. The train mapping consists of two chunks. The first one contains user_gender and user_age, saved as a CSV, and is further broken down into two files. For specifics of the layout, refer to the following example and consult the glossary. The second chunk contains the remaining columns and is saved in a single file. Notice that the order of columns is different in the second chunk - this is alright, as long as the order matches the order in that file (that is, columns in the .csv are also switched)
Let's break down the train source mapping. The table contains example data color-paired to the files containing it.
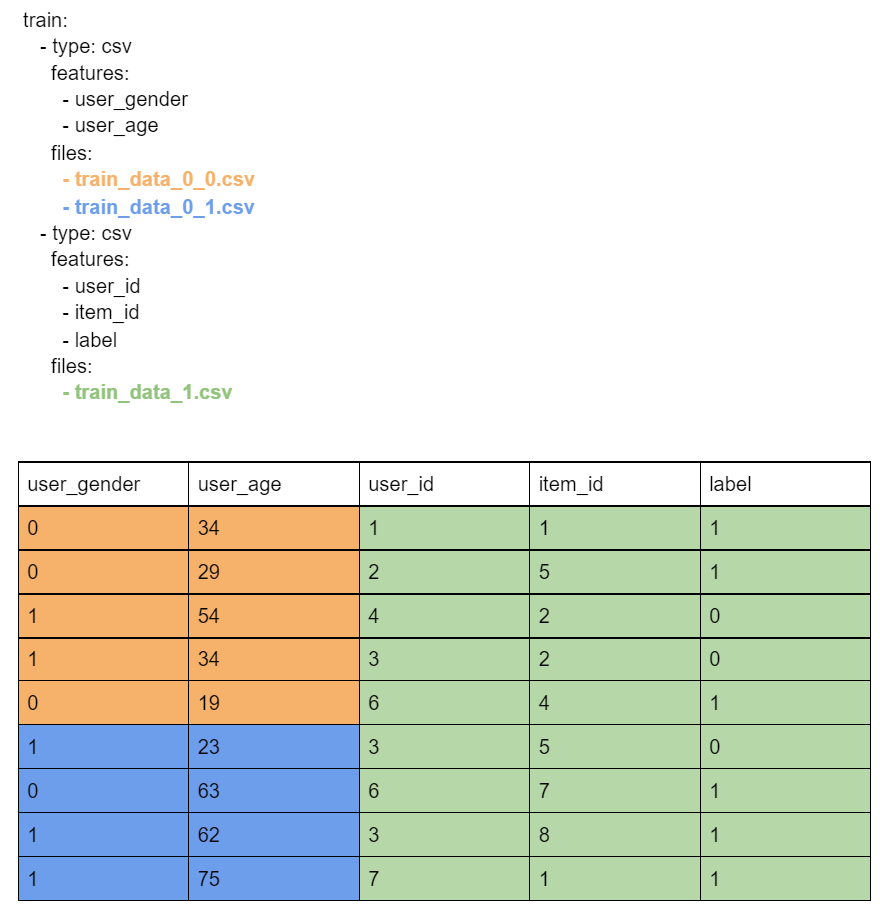
The channel spec describes how the data will be consumed. Four streams will be produced and available to the script/model. The feature specification does not specify what happens further: names of these streams are only lookup constants defined by the model/script. Based on this example, we can speculate that the model has three input channels: numeric_inputs, categorical_user_inputs, categorical_item_inputs, and one output channel: label. Feature names are internal to the FeatureSpec and can be freely modified.
BYO dataset functionality
In order to train any Recommendation model in NVIDIA Deep Learning Examples one can follow one of three possible ways:
-
One delivers already preprocessed dataset in the Intermediary Format supported by data loader used by the training script (different models use different data loaders) together with FeatureSpec yaml file describing at least specification of dataset, features and model channels
-
One uses a transcoding script
-
One delivers dataset in non-preprocessed form and uses preprocessing scripts that are a part of the model repository. In order to use already existing preprocessing scripts, the format of the dataset needs to match the one of the original datasets. This way, the FeatureSpec file will be generated automatically, but the user will have the same preprocessing as in the original model repository.
Glossary
The Dataset Feature Specification consists of three mandatory and one optional section:
feature_spec provides a base of features that may be referenced in other sections, along with their metadata.
Format: dictionary (feature name) => (metadata name => metadata value)
source_spec provides information necessary to extract features from the files that store them.
Format: dictionary (mapping name) => (list of chunks)
- Mappings are used to represent different versions of the dataset (think: train/validation/test, k-fold splits). A mapping is a list of chunks.
- Chunks are subsets of features that are grouped together for saving. For example, some formats may constrain data saved in one file to a single data type. In that case, each data type would correspond to at least one chunk. Another example where this might be used is to reduce file size and enable more parallel loading. Chunk description is a dictionary of three keys:
- type provides information about the format in which the data is stored. Not all formats are supported by all models.
- features is a list of features that are saved in a given chunk. Order of this list may matter: for some formats, it is crucial for assigning read data to the proper feature.
- files is a list of paths to files where the data is saved. For Feature Specification in yaml format, these paths are assumed to be relative to the yaml file's directory (basename). Order of this list matters: It is assumed that rows 1 to i appear in the first file, rows i+1 to j in the next one, etc.
- type provides information about the format in which the data is stored. Not all formats are supported by all models.
channel_spec determines how features are used. It is a mapping (channel name) => (list of feature names).
Channels are model specific magic constants. In general, data within a channel is processed using the same logic. Example channels: model output (labels), categorical ids, numerical inputs, user data, and item data.
metadata is a catch-all, wildcard section: If there is some information about the saved dataset that does not fit into the other sections, you can store it here.