MoFlow is a model for molecule generation that leverages Normalizing Flows. This implementation is an optimized version of the model in the original paper.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
MoFlow is a model for molecule generation that leverages Normalizing Flows. Normalizing Flows is a class of generative neural networks that directly models the probability density of the data. They consist of a sequence of invertible transformations that convert the input data that follow some hard-to-model distribution into a latent code that follows a normal distribution which can then be easily used for sampling.
MoFlow was first introduced by Chengxi Zang et al. in their paper titled "MoFlow: An Invertible Flow Model for Generating Molecular Graphs" (link).
The model enables you to generate novel molecules that have similar properties to your training data. In the case of ZINC dataset, which is used in this example, it allows you to navigate the chemical space of drug-like molecules and facilitate de-novo drug design. The differences between this version and the original implementation accompanying the paper are as follows:
- Loss calculation was separated from the neural network
- ActNorm layers were refactored and their initialization was moved outside of the forward pass
- Numerical stability of the training was improved by introducing gradient clipping
- Numerically-stable formulas for 1/sigmoid(x) and log(sigmoid(x)) were used in AffineCoupling and GraphAffineCoupling layers
- Network and data configurations were untangled to allow for more flexibility
- Linear transformations for node features were implemented using native Linear layers instead of custom GraphLinear layers
- Rescaled adjacency matrix was removed as it did not provide any benefit for the training
- Data pre-processing and loading were refactored
- Support for data-parallel multi-GPU training was added
- Option to capture CUDA graphs was added
- Execution of bond and atom models in was put in two parallel CUDA streams
- Option to compile model to TorchScript format was added
- Support for Automatic Mixed Precision training and inference was added
- FusedAdam optimizer from Apex was used instead of Adam
- Training parameters were tuned to achieve better generation quality
This model is trained with mixed precision using Tensor Cores on the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 1.43x faster than training with full precision while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
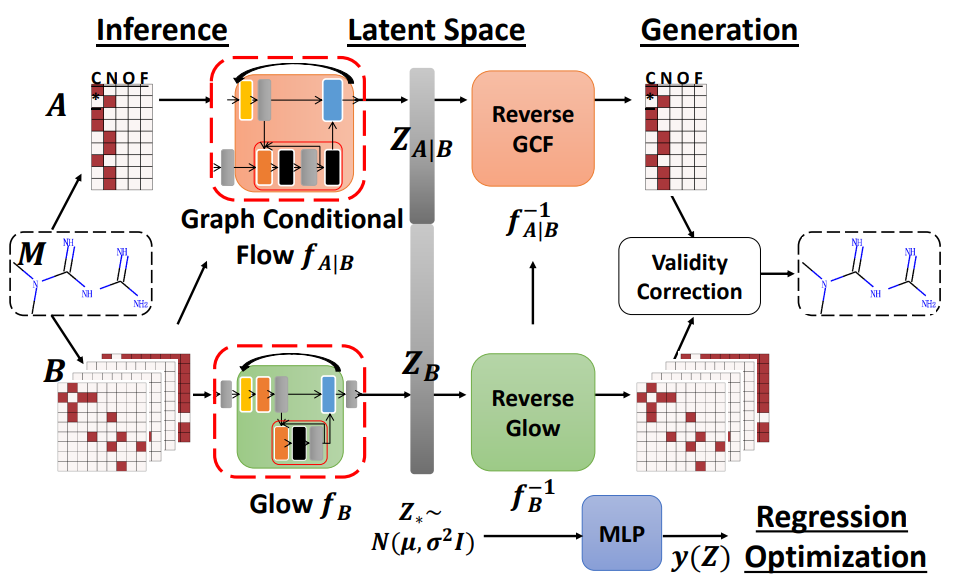
The MoFlow model consists of two parts. The first part, Glow, processes edges to convert an adjacency matrix into a latent vector Z_B. The second part, Graph Conditional Flow, processes nodes in the context of edges to produce conditional latent vector Z_{A|B}. Each part is a normalizing flow—a chain of invertible transformations with learnable parameters, which provide the ability to learn the distribution of the data.
Default configuration
The MoFlow model is built out of Normalizing Flows. It consists of two parts: Glow for processing edges and Graph Conditional Flow for processing nodes in the context of edges.
The following features were implemented in this model:
- Data-parallel multi-GPU training (DDP)
- Mixed precision training (autocast, gradient scaling)
- Just-in-time compilation
- Resumable training
- CUDA graphs capture
The following performance optimizations were implemented in this model:
- A series of matrix manipulations in the GraphConv layer was replaced with a single torch.einsum
- Tensors are created on the device with the desired dtype whenever possible
- Channels-last memory format was used for Glow
- Stream concurrency was introduced to allow for executing Glow and Graph Conditional Flow at the same time. The concurrency happens in both forward and backward passes, and it hides the runtime of the smaller sub-model. Performance improvement is the most prominent for small batch sizes.
- Number of nodes in the graph is now independent of the maximum number of atoms in the dataset. This provides more flexibility and allows the use of shapes divisible by eight for better Tensor Cores usage.
- FusedAdam optimizer is used instead of native Adam.
- Normalization of the adjacency matrix was removed, as it did not benefit the training and required additional computation.
Feature support matrix
This model supports the following features::
| Feature | MoFlow |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Distributed data parallel (DDP) | Yes |
| CUDA Graphs | Yes |
Features
Distributed data parallel (DDP)
DistributedDataParallel (DDP) implements data parallelism at the module level that can run across multiple GPUs or machines.
Automatic Mixed Precision (AMP)
This implementation uses the native PyTorch AMP implementation of mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just a few lines of code. A detailed explanation of mixed precision can be found in the next section.
CUDA Graphs
This feature allows launching multiple GPU operations through a single CPU operation. The result is a vast reduction in CPU overhead. The benefits are particularly pronounced when training with relatively small batch sizes. The CUDA Graphs feature has been available through a native PyTorch API starting from PyTorch v1.10.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in NVIDIA Volta, and following with both the NVIDIA Turing and NVIDIA Ampere Architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
AMP enables mixed precision training on NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere GPU architectures automatically. The PyTorch framework code makes all necessary model changes internally.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
- APEX tools for mixed precision training, refer to the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
Mixed precision is enabled in PyTorch by using the native Automatic Mixed Precision package, which casts variables to half-precision upon retrieval while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In PyTorch, loss scaling can be applied automatically using a GradScaler.
Automatic Mixed Precision makes all the adjustments internally in PyTorch, providing two benefits over manual operations. First, programmers do not need to modify network model code, reducing development and maintenance efforts. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running PyTorch models.
To enable mixed precision, you can simply use the --amp flag when running the training or inference scripts.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Normalizing flow - a class of generative neural networks that directly models the probability density of the data.
Molecular graph - representation of a molecule, in which nodes correspond to atoms and edges correspond to chemical bonds
SMILES format - a format that allows representing a molecule with a string of characters