The Jasper model is an end-to-end neural acoustic model for automatic speech recognition (ASR).
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
This repository provides an implementation of the Jasper model in PyTorch from the paper Jasper: An End-to-End Convolutional Neural Acoustic Model https://arxiv.org/pdf/1904.03288.pdf.
The Jasper model is an end-to-end neural acoustic model for automatic speech recognition (ASR) that provides near state-of-the-art results on LibriSpeech among end-to-end ASR models without any external data. The Jasper architecture of convolutional layers was designed to facilitate fast GPU inference, by allowing whole sub-blocks to be fused into a single GPU kernel. This is important for meeting strict real-time requirements of ASR systems in deployment.
The results of the acoustic model are combined with the results of external language models to get the top-ranked word sequences corresponding to a given audio segment. This post-processing step is called decoding.
This repository is a PyTorch implementation of Jasper and provides scripts to train the Jasper 10x5 model with dense residuals from scratch on the Librispeech dataset to achieve the greedy decoding results of the original paper. The original reference code provides Jasper as part of a research toolkit in TensorFlow openseq2seq. This repository provides a simple implementation of Jasper with scripts for training and replicating the Jasper paper results. This includes data preparation scripts, training and inference scripts. Both training and inference scripts offer the option to use Automatic Mixed Precision (AMP) to benefit from Tensor Cores for better performance.
In addition to providing the hyperparameters for training a model checkpoint, we publish a thorough inference analysis across different NVIDIA GPU platforms, for example, DGX A100, DGX-1, DGX-2 and T4.
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 3x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
The original paper takes the output of the Jasper acoustic model and shows results for 3 different decoding variations: greedy decoding, beam search with a 6-gram language model and beam search with further rescoring of the best ranked hypotheses with Transformer XL, which is a neural language model. Beam search and the rescoring with the neural language model scores are run on CPU and result in better word error rates compared to greedy decoding. This repository provides instructions to reproduce greedy decoding results. To run beam search or rescoring with TransformerXL, use the following scripts from the openseq2seq repository: https://github.com/NVIDIA/OpenSeq2Seq/blob/master/scripts/decode.py https://github.com/NVIDIA/OpenSeq2Seq/tree/master/external_lm_rescore
Model architecture
Details on the model architecture can be found in the paper Jasper: An End-to-End Convolutional Neural Acoustic Model.
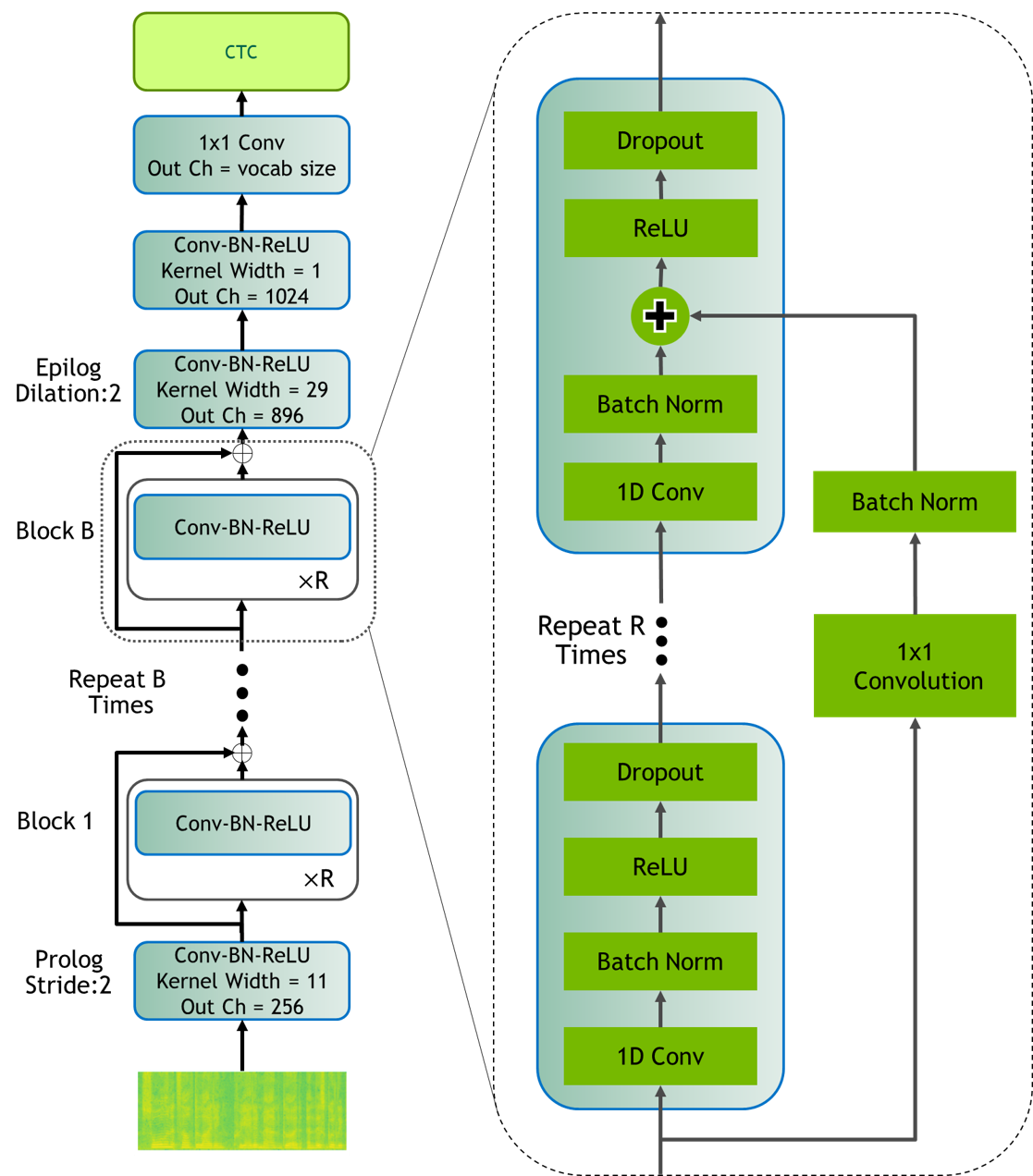 | 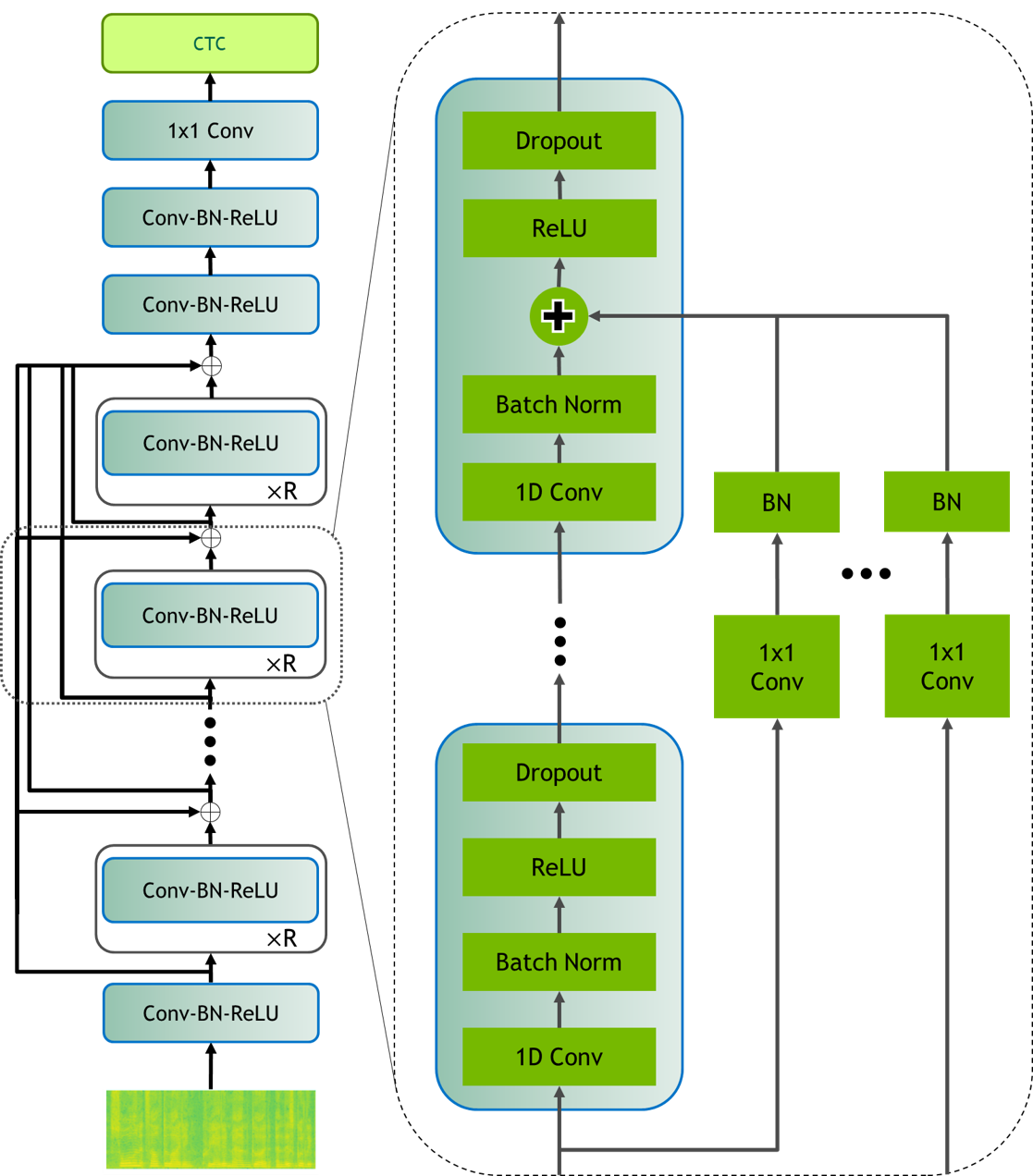 |
|---|---|
| Figure 1: Jasper BxR model: B- number of blocks, R- number of sub-blocks | Figure 2: Jasper Dense Residual |
Jasper is an end-to-end neural acoustic model that is based on convolutions. In the audio processing stage, each frame is transformed into mel-scale spectrogram features, which the acoustic model takes as input and outputs a probability distribution over the vocabulary for each frame. The acoustic model has a modular block structure and can be parametrized accordingly: a Jasper BxR model has B blocks, each consisting of R repeating sub-blocks.
Each sub-block applies the following operations in sequence: 1D-Convolution, Batch Normalization, ReLU activation, and Dropout.
Each block input is connected directly to the last subblock of all following blocks via a residual connection, which is referred to as dense residual in the paper.
Every block differs in kernel size and number of filters, which are increasing in size from the bottom to the top layers.
Irrespective of the exact block configuration parameters B and R, every Jasper model has four additional convolutional blocks:
one immediately succeeding the input layer (Prologue) and three at the end of the B blocks (Epilogue).
The Prologue is to decimate the audio signal in time in order to process a shorter time sequence for efficiency. The Epilogue with dilation captures a bigger context around an audio time step, which decreases the model word error rate (WER). The paper achieves best results with Jasper 10x5 with dense residual connections, which is also the focus of this repository and is in the following referred to as Jasper Large.
Default configuration
The following features were implemented in this model:
- GPU-supported feature extraction with data augmentation options SpecAugment and Cutout
- offline and online Speed Perturbation
- data-parallel multi-GPU training and evaluation
- AMP with dynamic loss scaling for Tensor Core training
- FP16 inference
Competitive training results and analysis is provided for the following Jasper model configuration
| Model | Number of Blocks | Number of Subblocks | Max sequence length | Number of Parameters |
|---|---|---|---|---|
| Jasper Large | 10 | 5 | 16.7 s | 333 M |
Feature support matrix
The following features are supported by this model.
| Feature | Jasper |
|---|---|
| Apex AMP | Yes |
| Apex DistributedDataParallel | Yes |
Features
Apex AMP - a tool that enables Tensor Core-accelerated training. Refer to the Enabling mixed precision section for more details.
Apex
DistributedDataParallel -
a module wrapper that enables easy multiprocess distributed data parallel
training, similar to
torch.nn.parallel.DistributedDataParallel.
DistributedDataParallel is optimized for use with
NCCL. It achieves high performance by
overlapping communication with computation during backward() and bucketing
smaller gradient transfers to reduce the total number of transfers required.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see theMixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
- APEX tools for mixed precision training, see the NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch.
Enabling mixed precision
For training, mixed precision can be enabled by setting the flag: train.py --amp. When using bash helper scripts: scripts/train.sh scripts/inference.sh, etc., mixed precision can be enabled with env variable AMP=true.
Mixed precision is enabled in PyTorch by using the Automatic Mixed Precision
(AMP) library from APEX that casts variables
to half-precision upon retrieval, while storing variables in single-precision
format. Furthermore, to preserve small gradient magnitudes in backpropagation,
a loss
scaling
step must be included when applying gradients. In PyTorch, loss scaling can be
easily applied by using scale_loss() method provided by AMP. The scaling
value to be used can be
dynamic or fixed.
For an in-depth walk through on AMP, check out sample usage here. APEX is a PyTorch extension that contains utility libraries, such as AMP, which require minimal network code changes to leverage Tensor Cores performance.
The following steps were needed to enable mixed precision training in Jasper:
- Import AMP from APEX (file:
train.py):
from apex import amp
- Initialize AMP and wrap the model and the optimizer
model, optimizer = amp.initialize(
min_loss_scale=1.0,
models=model,
optimizers=optimizer,
opt_level='O1')
- Apply
scale_losscontext manager
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Acoustic model Assigns a probability distribution over a vocabulary of characters given an audio frame.
Language Model Assigns a probability distribution over a sequence of words. Given a sequence of words, it assigns a probability to the whole sequence.
Pre-training Training a model on vast amounts of data on the same (or different) task to build general understandings.
Automatic Speech Recognition (ASR) Uses both acoustic model and language model to output the transcript of an input audio signal.