HiFi-GAN model implements a spectrogram inversion model that allows to synthesize speech waveforms from mel-spectrograms.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
This repository provides a PyTorch implementation of the HiFi-GAN model described in the paper HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. The HiFi-GAN model implements a spectrogram inversion model that allows to synthesize speech waveforms from mel-spectrograms. It follows the generative adversarial network (GAN) paradigm, and is composed of a generator and a discriminator. After training, the generator is used for synthesis, and the discriminator is discarded.
Our implementation is based on the one published by the authors of the paper. We modify the original hyperparameters and provide an alternative training recipe, which enables training on larger batches and faster convergence. HiFi-GAN is trained on a publicly available LJ Speech dataset. The samples demonstrate speech synthesized with our publicly available FastPitch and HiFi-GAN checkpoints.
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta and the NVIDIA Ampere GPU architectures and evaluated on Volta, Turing and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 2.5x faster than training without Tensor Cores while experiencing the benefits of mixed-precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
The entire model is composed of a generator and two discriminators. Both discriminators can be further divided into smaller sub-networks, that work at different resolutions. The loss functions take as inputs intermediate feature maps and outputs of those sub-networks. After training, the generator is used for synthesis, and the discriminators are discarded. All three components are convolutional networks with different architectures.
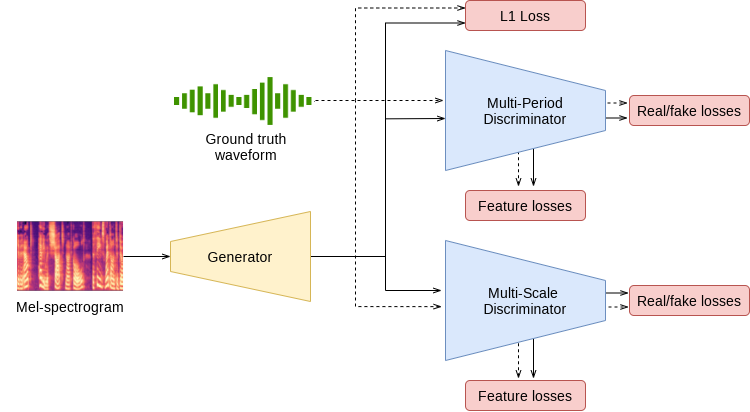
Figure 1. The architecture of HiFi-GAN
Default configuration
The following features were implemented in this model:
- data-parallel multi-GPU training,
- training and inference with mixed precision using Tensor Cores,
- gradient accumulation for reproducible results regardless of the number of GPUs.
The training recipe we provide for the model, recreates the v1 model from the HiFi-GAN paper,
which is the largest and has the highest quality of all models described in the paper.
Mixed precision training and memory optimizations allowed us to increase batch size and throughput significantly.
In effect, we modify some hyperparameters of the v1 recipe.
Feature support matrix
The following features are supported by this model.
| Feature | HiFi-GAN |
|---|---|
| Automatic mixed precision (AMP) | Yes |
| Distributed data parallel (DDP) | Yes |
Features
Automatic Mixed Precision (AMP) This implementation uses native PyTorch AMP implementation of mixed precision training. It allows us to use FP16 training with FP32 master weights by modifying just a few lines of code.
DistributedDataParallel (DDP) The model uses PyTorch Lightning implementation of distributed data parallelism at the module level which can run across multiple machines.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
Enabling mixed precision
For training and inference, mixed precision can be enabled by adding the --amp flag.
Mixed precision is using native PyTorch implementation.
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models that require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Multi-Period Discriminator A sub-network that extracts patterns from the data that occur periodically (for example, every N time steps).
Multi-Scale Discriminator A sub-network that extracts patterns from the data at different resolutions of the input signal. Lower resolutions are obtained by average-pooling of the signal.
Fine-tuning Training an already pretrained model further using a task specific dataset for subject-specific refinements, by adding task-specific layers on top if required.