GPUNet is a new family of Convolutional Neural Networks crafted by NVIDIA AI.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
Developed by NVIDIA, GPUNet differs from the current ConvNets in three aspects:
-
Designed by AI: we built an AI agent to establish SOTA GPUNet out of our years of research in Neural Architecture Search. Powered by Selene supercomputer, our AI agent can automatically orchestrate hundreds of GPUs to meticulously trade-off sophisticated design decisions w.r.t multiple design goals without intervening by the domain experts.
-
Co-designed with NVIDIA TensorRT and GPU: GPUNet only considers the most relevant factors to the model accuracy and the TensorRT inference latency, promoting GPU friendly operators (for example, larger filters) over memory-bound operators (for example, fancy activations), therefore delivering the SOTA GPU latency and the accuracy on ImageNet.
-
TensorRT deployment-ready: All the GPUNet reported latencies are after the optimization from TensorRT, including kernel fusion, quantization, etc., so GPUNet is directly deployable to users.
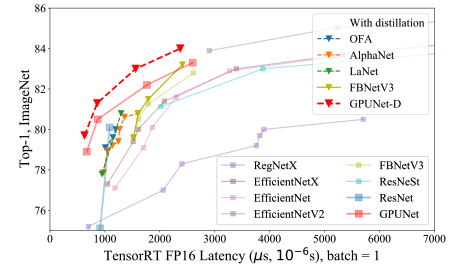
Because of better design trade-off and hardware and software co-design, GPUNet has established new SOTA latency and accuracy Pareto frontier on ImageNet. Specifically, GPUNet is up to 2x faster than EfficentNet, EfficientNet-X and FBNetV3. Our CVPR-2022 paper provides extensive evaluation results aginsts other networks.
Model architecture
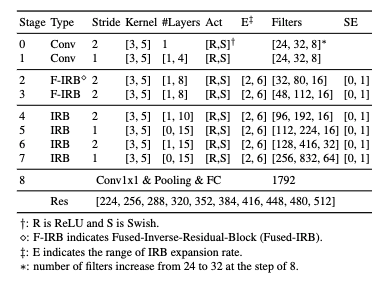
The above table describes the general structure of GPUNet, which consists of 8 stages, and we search for the configurations of each stage. The layers within a stage share the same configurations. The first two stages are to search for the head configurations using convolutions. Inspired by EfficientNet-V2, the 2 and 3 stages use Fused Inverted Residual Blocks(IRB); however, we observed the increasing latency after replacing the rest IRB with Fused-IRB. Therefore, from stages 4 to 7, we use IRB as the primary layer. The column #Layers shows the range of #Layers in the stage, for example, [3, 10] at stage 4 means that the stage can have three to 10 IRBs, and the column filters shows the range of filters for the layers in the stage. We also tuned the expansion ratio, activation types, kernel sizes, and the Squeeze Excitation(SE) layer inside the IRB/Fused-IRB. Finally, the dimensions of the input image increased from 224 to 512 at step 32.
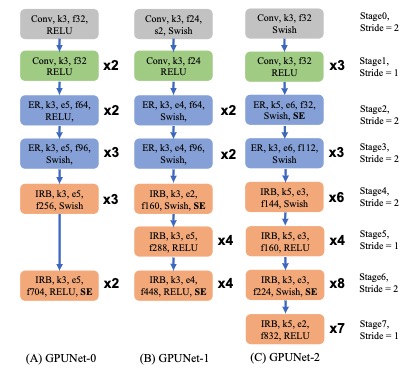
GPUNet has provided seven specific model architectures at different latencies. You can easily query the architecture details from the JSON formatted model (for example, those in eval.py). The following figure describes GPUNet-0, GPUNet-1, and GPUNet-2 in the paper. Note that only the first IRB's stride is two and the stride of the rest IRBs is 1 in stages 2, 3, 4, and 6.
Default configuration
- Training features:
- Customize the training pipeline in Timm to support the distillation.
- Here provides an example of training hyper-parameters with distillation.
- All the features in Timm, including
- Random data augmentation, mean = 9, std = 0.5.
- Exponential Moving Average (EMA).
- Rmsproptf optimizer.
- Multi-GPU training.
- Automatic mixed precision (AMP).
- GPUNet can be further improved with other training hacks such as Mixup or drop path regularization. More hacks are available at Timm.
- The exact training hyper-parameters to reproduce the GPUNet results can be found here.
- Customize the training pipeline in Timm to support the distillation.
- Inference features:
- Test the accuracy of pre-trained GPUNet.
- Save GPUNet to the ONNX files for the latency benchmarking.
Feature support matrix
This model supports the following features:
| Feature | GPUNet |
|---|---|
| Multi-GPU training | ✓ |
| Automatic mixed precision (AMP) | ✓ |
| Distillation | ✓ |
Features
Multi-GPU training: we re-use the same training pipeline from Timm to train GPUNet. Timm has adopted NCCL to optimize the multi-GPU training efficiency.
Automatic Mixed Precision (AMP): mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speed-up by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network.
Timm supports AMP by default and only requires the '--amp' flag to enable the AMP training.
Distillation: originally introduced in Hinton's seminal paper, knowledge distillation uses a larger and better teacher network to supervise the training of a student network in addition to the ground truth. Generally the final accuracy of a student network is better than the training without a teacher; for example, ~+2% on ImageNet.
We customized Timm to support the distillation. The teacher model can be any model supported by Timm. We demonstrate the usage of distillation in Training with distillation.