EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, being an order-of-magnitude smaller and faster.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
Model architecture
EfficientNet v1 is developed based on AutoML and Compound Scaling. In particular, a mobile-size baseline network called EfficientNet v1-B0 is developed from AutoML MNAS Mobile framework, the building block is mobile inverted bottleneck MBConv with squeeze-and-excitation optimization. Then, through a compound scaling method, this baseline is scaled up to obtain EfficientNet v1-B1 to B7.
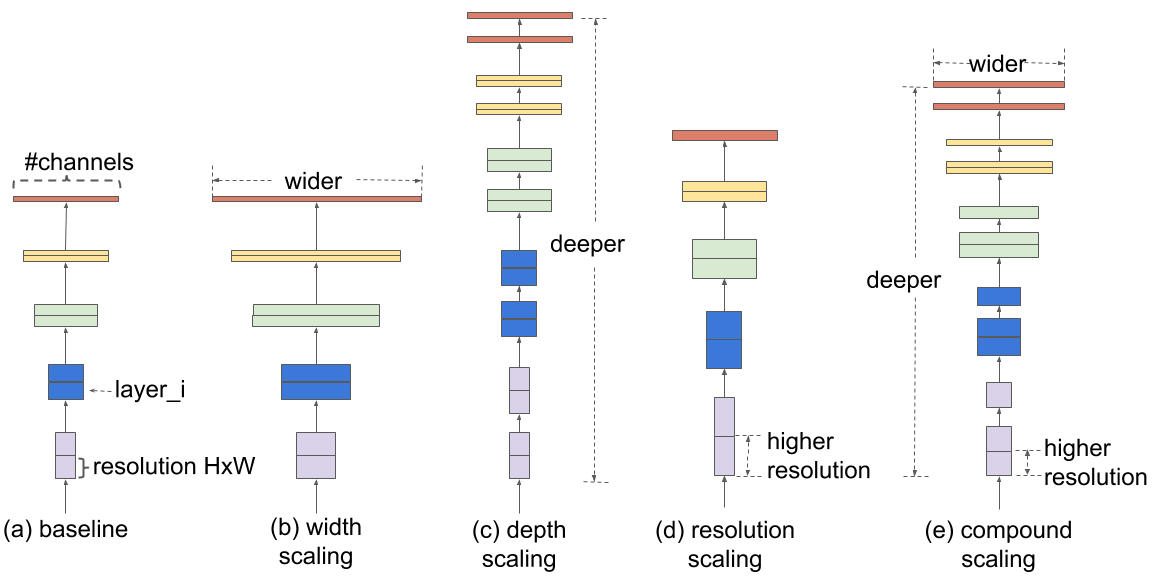
Default configuration
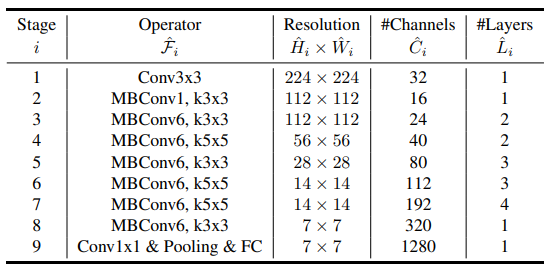
Here is the Baseline EfficientNet v1-B0 structure.
The following features are supported by this implementation:
-
General:
- XLA support
- Mixed precision support
- Multi-GPU support using Horovod
- Multi-node support using Horovod
- Cosine LR Decay
-
Inference:
- Support for inference on a single image is included
- Support for inference on a batch of images is included
Feature support matrix
| Feature | EfficientNet |
|---|---|
| Horovod Multi-GPU training (NCCL) | Yes |
| Multi-GPU training | Yes |
| Multi-node training | Yes |
| Automatic mixed precision (AMP) | Yes |
| XLA | Yes |
| Gradient Accumulation | Yes |
| Stage-wise Training | Yes |
Features
Multi-GPU training with Horovod
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, refer to example sources in this repository or refer to the TensorFlow tutorial.
Multi-node training with Horovod
Our model also uses Horovod to implement efficient multi-node training.
Automatic Mixed Precision (AMP)
Computation graphs can be modified by TensorFlow on runtime to support mixed precision training. A detailed explanation of mixed precision can be found in Appendix.
Gradient Accumulation
Gradient Accumulation is supported through a custom train_step function. This feature is enabled only when grad_accum_steps is greater than 1.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in NVIDIA Volta, and following with both the NVIDIA Turing and NVIDIA Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training previously required two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, refer to the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, refer to Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension, which casts variables to half-precision upon retrieval while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
To enable mixed precision, you can simply add the --use_amp to the command-line used to run the model. This will enable the following code:
if params.use_amp:
policy = tf.keras.mixed_precision.experimental.Policy('mixed_float16', loss_scale='dynamic')
tf.keras.mixed_precision.experimental.set_policy(policy)
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.