EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, being an order-of-magnitude smaller and faster.
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA's latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
To benchmark training, run:
-
For 1 GPU
- FP32 (V100 GPUs only)
python ./launch.py --model efficientnet-<version> --precision FP32 --mode benchmark_training --platform DGX1V <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100 - TF32 (A100 GPUs only)
python ./launch.py --model efficientnet-<version> --precision TF32 --mode benchmark_training --platform DGXA100 <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100 - AMP
python ./launch.py --model efficientnet-<version> --precision AMP --mode benchmark_training --platform <DGX1V|DGXA100> <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100
- FP32 (V100 GPUs only)
-
For multiple GPUs
- FP32 (V100 GPUs only)
python ./launch.py --model efficientnet-<version> --precision FP32 --mode benchmark_training --platform DGX1V <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100 - TF32 (A100 GPUs only)
python ./multiproc.py --nproc_per_node 8 ./launch.py --model efficientnet-<version> --precision TF32 --mode benchmark_training --platform DGXA100 <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100 - AMP
python ./multiproc.py --nproc_per_node 8 ./launch.py --model efficientnet-<version> --precision AMP --mode benchmark_training --platform <DGX1V|DGXA100> <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100
- FP32 (V100 GPUs only)
Each of these scripts will run 100 iterations and save results in the benchmark.json file.
Inference performance benchmark
To benchmark inference, run:
- FP32 (V100 GPUs only)
python ./launch.py --model efficientnet-<version> --precision FP32 --mode benchmark_inference --platform DGX1V <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100
- TF32 (A100 GPUs only)
python ./launch.py --model efficientnet-<version> --precision TF32 --mode benchmark_inference --platform DGXA100 <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100
- AMP
python ./launch.py --model efficientnet-<version> --precision AMP --mode benchmark_inference --platform <DGX1V|DGXA100> <path to imagenet> --raport-file benchmark.json --epochs 1 --prof 100
Each of these scripts will run 100 iterations and save results in the benchmark.json file.
Results
Our results were obtained by running the applicable training script in the pytorch-21.03 NGC container.
To achieve these same results, follow the steps in the Quick Start Guide.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the applicable efficientnet/training/<AMP|TF32>/*.sh training script in the PyTorch 20.12 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs.
| Model | Epochs | GPUs | Top1 accuracy - TF32 | Top1 accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|---|
| efficientnet-b0 | 400 | 8 | 77.16 +/- 0.07 | 77.42 +/- 0.11 | 19 | 11 | 1.727 |
| efficientnet-b4 | 400 | 8 | 82.82 +/- 0.04 | 82.85 +/- 0.09 | 126 | 66 | 1.909 |
| efficientnet-widese-b0 | 400 | 8 | 77.84 +/- 0.08 | 77.84 +/- 0.02 | 19 | 10 | 1.900 |
| efficientnet-widese-b4 | 400 | 8 | 83.13 +/- 0.11 | 83.1 +/- 0.09 | 126 | 66 | 1.909 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the applicable efficientnet/training/<AMP|FP32>/*.sh training script in the PyTorch 20.12 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
| Model | Epochs | GPUs | Top1 accuracy - FP32 | Top1 accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|---|---|---|---|---|---|---|---|
| efficientnet-b0 | 400 | 8 | 77.02 +/- 0.04 | 77.17 +/- 0.08 | 34 | 24 | 1.417 |
| efficientnet-widese-b0 | 400 | 8 | 77.59 +/- 0.16 | 77.69 +/- 0.12 | 35 | 24 | 1.458 |
Example plots
The following images show an A100 run.
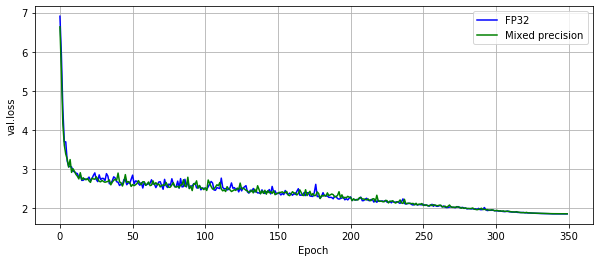
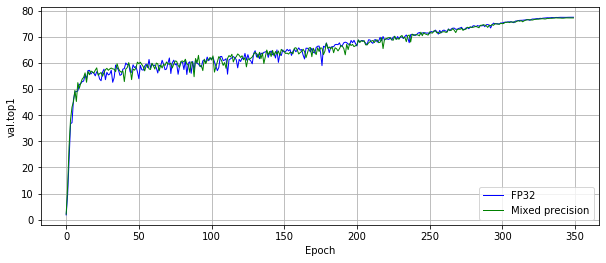
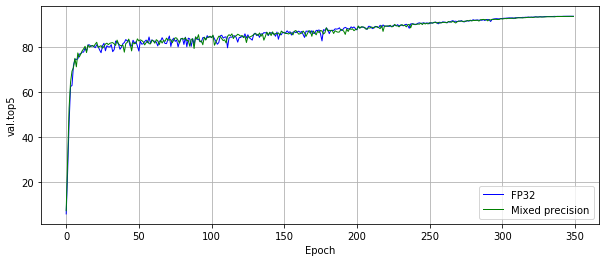
Training performance results
Training performance: NVIDIA A100 (8x A100 80GB)
Our results were obtained by running the applicable efficientnet/training/<AMP|TF32>/*.sh training script in the PyTorch 21.03 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs.
| Model | GPUs | TF32 | Throughput - mixed precision | Throughput speedup (TF32 to mixed precision) | TF32 Strong Scaling | Mixed Precision Strong Scaling |
|---|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 1078 img/s | 2489 img/s | 2.3 x | 1.0 x | 1.0 x |
| efficientnet-b0 | 8 | 8193 img/s | 16652 img/s | 2.03 x | 7.59 x | 6.68 x |
| efficientnet-b0 | 16 | 16137 img/s | 29332 img/s | 1.81 x | 14.96 x | 11.78 x |
| efficientnet-b4 | 1 | 157 img/s | 331 img/s | 2.1 x | 1.0 x | 1.0 x |
| efficientnet-b4 | 8 | 1223 img/s | 2570 img/s | 2.1 x | 7.76 x | 7.75 x |
| efficientnet-b4 | 16 | 2417 img/s | 4813 img/s | 1.99 x | 15.34 x | 14.51 x |
| efficientnet-b4 | 32 | 4813 img/s | 9425 img/s | 1.95 x | 30.55 x | 28.42 x |
| efficientnet-b4 | 64 | 9146 img/s | 18900 img/s | 2.06 x | 58.05 x | 57.0 x |
| efficientnet-widese-b0 | 1 | 1078 img/s | 2512 img/s | 2.32 x | 1.0 x | 1.0 x |
| efficientnet-widese-b0 | 8 | 8244 img/s | 16368 img/s | 1.98 x | 7.64 x | 6.51 x |
| efficientnet-widese-b0 | 16 | 16062 img/s | 29798 img/s | 1.85 x | 14.89 x | 11.86 x |
| efficientnet-widese-b4 | 1 | 157 img/s | 331 img/s | 2.1 x | 1.0 x | 1.0 x |
| efficientnet-widese-b4 | 8 | 1223 img/s | 2585 img/s | 2.11 x | 7.77 x | 7.8 x |
| efficientnet-widese-b4 | 16 | 2399 img/s | 5041 img/s | 2.1 x | 15.24 x | 15.21 x |
| efficientnet-widese-b4 | 32 | 4616 img/s | 9379 img/s | 2.03 x | 29.32 x | 28.3 x |
| efficientnet-widese-b4 | 64 | 9140 img/s | 18516 img/s | 2.02 x | 58.07 x | 55.88 x |
Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the applicable efficientnet/training/<AMP|FP32>/*.sh training script in the PyTorch 21.03 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
| Model | GPUs | FP32 | Throughput - mixed precision | Throughput speedup (FP32 to mixed precision) | FP32 Strong Scaling | Mixed Precision Strong Scaling |
|---|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 655 img/s | 1301 img/s | 1.98 x | 1.0 x | 1.0 x |
| efficientnet-b0 | 8 | 4672 img/s | 7789 img/s | 1.66 x | 7.12 x | 5.98 x |
| efficientnet-b4 | 1 | 83 img/s | 204 img/s | 2.46 x | 1.0 x | 1.0 x |
| efficientnet-b4 | 8 | 616 img/s | 1366 img/s | 2.21 x | 7.41 x | 6.67 x |
| efficientnet-widese-b0 | 1 | 655 img/s | 1299 img/s | 1.98 x | 1.0 x | 1.0 x |
| efficientnet-widese-b0 | 8 | 4592 img/s | 7875 img/s | 1.71 x | 7.0 x | 6.05 x |
| efficientnet-widese-b4 | 1 | 83 img/s | 204 img/s | 2.45 x | 1.0 x | 1.0 x |
| efficientnet-widese-b4 | 8 | 612 img/s | 1356 img/s | 2.21 x | 7.34 x | 6.63 x |
Training performance: NVIDIA DGX-1 (8x V100 32GB)
Our results were obtained by running the applicable efficientnet/training/<AMP|FP32>/*.sh training script in the PyTorch 21.03 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
| Model | GPUs | FP32 | Throughput - mixed precision | Throughput speedup (FP32 to mixed precision) | FP32 Strong Scaling | Mixed Precision Strong Scaling |
|---|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 646 img/s | 1401 img/s | 2.16 x | 1.0 x | 1.0 x |
| efficientnet-b0 | 8 | 4937 img/s | 8615 img/s | 1.74 x | 7.63 x | 6.14 x |
| efficientnet-b4 | 1 | 36 img/s | 89 img/s | 2.44 x | 1.0 x | 1.0 x |
| efficientnet-b4 | 8 | 641 img/s | 1565 img/s | 2.44 x | 17.6 x | 17.57 x |
| efficientnet-widese-b0 | 1 | 281 img/s | 603 img/s | 2.14 x | 1.0 x | 1.0 x |
| efficientnet-widese-b0 | 8 | 4924 img/s | 8870 img/s | 1.8 x | 17.49 x | 14.7 x |
| efficientnet-widese-b4 | 1 | 36 img/s | 89 img/s | 2.45 x | 1.0 x | 1.0 x |
| efficientnet-widese-b4 | 8 | 639 img/s | 1556 img/s | 2.43 x | 17.61 x | 17.44 x |
Inference performance results
Inference performance: NVIDIA A100 (1x A100 80GB)
Our results were obtained by running the applicable efficientnet/inference/<AMP|FP32>/*.sh inference script in the PyTorch 21.03 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
TF32 Inference Latency
| Model | Batch Size | Throughput Avg | Latency Avg | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 130 img/s | 9.33 ms | 7.95 ms | 9.0 ms |
| efficientnet-b0 | 2 | 262 img/s | 9.39 ms | 8.51 ms | 9.5 ms |
| efficientnet-b0 | 4 | 503 img/s | 9.68 ms | 9.53 ms | 10.78 ms |
| efficientnet-b0 | 8 | 1004 img/s | 9.85 ms | 9.89 ms | 11.49 ms |
| efficientnet-b0 | 16 | 1880 img/s | 10.27 ms | 10.34 ms | 11.19 ms |
| efficientnet-b0 | 32 | 3401 img/s | 11.46 ms | 12.51 ms | 14.39 ms |
| efficientnet-b0 | 64 | 4656 img/s | 19.58 ms | 14.52 ms | 16.63 ms |
| efficientnet-b0 | 128 | 5001 img/s | 31.03 ms | 25.72 ms | 28.34 ms |
| efficientnet-b0 | 256 | 5154 img/s | 60.71 ms | 49.44 ms | 54.99 ms |
| efficientnet-b4 | 1 | 69 img/s | 16.22 ms | 14.87 ms | 15.34 ms |
| efficientnet-b4 | 2 | 133 img/s | 16.84 ms | 16.49 ms | 17.72 ms |
| efficientnet-b4 | 4 | 259 img/s | 17.33 ms | 16.39 ms | 19.67 ms |
| efficientnet-b4 | 8 | 491 img/s | 18.22 ms | 18.09 ms | 19.51 ms |
| efficientnet-b4 | 16 | 606 img/s | 28.28 ms | 26.55 ms | 26.84 ms |
| efficientnet-b4 | 32 | 651 img/s | 51.08 ms | 49.39 ms | 49.61 ms |
| efficientnet-b4 | 64 | 684 img/s | 96.23 ms | 93.54 ms | 93.78 ms |
| efficientnet-b4 | 128 | 700 img/s | 195.22 ms | 182.17 ms | 182.42 ms |
| efficientnet-b4 | 256 | 702 img/s | 380.01 ms | 361.81 ms | 371.64 ms |
| efficientnet-widese-b0 | 1 | 130 img/s | 9.49 ms | 8.76 ms | 9.68 ms |
| efficientnet-widese-b0 | 2 | 265 img/s | 9.25 ms | 8.51 ms | 9.75 ms |
| efficientnet-widese-b0 | 4 | 520 img/s | 9.42 ms | 8.67 ms | 9.97 ms |
| efficientnet-widese-b0 | 8 | 996 img/s | 12.27 ms | 9.69 ms | 11.31 ms |
| efficientnet-widese-b0 | 16 | 1916 img/s | 10.2 ms | 10.29 ms | 11.3 ms |
| efficientnet-widese-b0 | 32 | 3293 img/s | 11.71 ms | 13.0 ms | 14.57 ms |
| efficientnet-widese-b0 | 64 | 4639 img/s | 16.21 ms | 14.61 ms | 16.29 ms |
| efficientnet-widese-b0 | 128 | 4997 img/s | 30.81 ms | 25.76 ms | 26.02 ms |
| efficientnet-widese-b0 | 256 | 5166 img/s | 73.68 ms | 49.39 ms | 55.74 ms |
| efficientnet-widese-b4 | 1 | 68 img/s | 16.41 ms | 15.14 ms | 16.59 ms |
| efficientnet-widese-b4 | 2 | 135 img/s | 16.65 ms | 15.52 ms | 17.93 ms |
| efficientnet-widese-b4 | 4 | 251 img/s | 17.74 ms | 17.29 ms | 20.47 ms |
| efficientnet-widese-b4 | 8 | 501 img/s | 17.75 ms | 17.12 ms | 18.01 ms |
| efficientnet-widese-b4 | 16 | 590 img/s | 28.94 ms | 27.29 ms | 27.81 ms |
| efficientnet-widese-b4 | 32 | 651 img/s | 50.96 ms | 49.34 ms | 49.55 ms |
| efficientnet-widese-b4 | 64 | 683 img/s | 99.28 ms | 93.65 ms | 93.88 ms |
| efficientnet-widese-b4 | 128 | 700 img/s | 189.81 ms | 182.3 ms | 182.58 ms |
| efficientnet-widese-b4 | 256 | 702 img/s | 379.36 ms | 361.84 ms | 366.05 ms |
Mixed Precision Inference Latency
| Model | Batch Size | Throughput Avg | Latency Avg | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 105 img/s | 11.21 ms | 9.9 ms | 12.55 ms |
| efficientnet-b0 | 2 | 214 img/s | 11.01 ms | 10.06 ms | 11.89 ms |
| efficientnet-b0 | 4 | 412 img/s | 11.45 ms | 11.73 ms | 13.0 ms |
| efficientnet-b0 | 8 | 803 img/s | 11.78 ms | 11.59 ms | 14.2 ms |
| efficientnet-b0 | 16 | 1584 img/s | 11.89 ms | 11.9 ms | 13.63 ms |
| efficientnet-b0 | 32 | 2915 img/s | 13.03 ms | 14.79 ms | 17.35 ms |
| efficientnet-b0 | 64 | 6315 img/s | 12.71 ms | 13.59 ms | 15.27 ms |
| efficientnet-b0 | 128 | 9311 img/s | 18.78 ms | 15.34 ms | 17.99 ms |
| efficientnet-b0 | 256 | 10239 img/s | 39.05 ms | 24.97 ms | 29.24 ms |
| efficientnet-b4 | 1 | 53 img/s | 20.45 ms | 19.06 ms | 20.36 ms |
| efficientnet-b4 | 2 | 109 img/s | 20.01 ms | 19.74 ms | 21.5 ms |
| efficientnet-b4 | 4 | 212 img/s | 20.6 ms | 19.88 ms | 22.37 ms |
| efficientnet-b4 | 8 | 416 img/s | 21.02 ms | 21.46 ms | 24.82 ms |
| efficientnet-b4 | 16 | 816 img/s | 21.53 ms | 22.91 ms | 26.06 ms |
| efficientnet-b4 | 32 | 1208 img/s | 28.4 ms | 26.77 ms | 28.3 ms |
| efficientnet-b4 | 64 | 1332 img/s | 50.55 ms | 48.23 ms | 48.49 ms |
| efficientnet-b4 | 128 | 1418 img/s | 95.84 ms | 90.12 ms | 95.76 ms |
| efficientnet-b4 | 256 | 1442 img/s | 191.48 ms | 176.19 ms | 189.04 ms |
| efficientnet-widese-b0 | 1 | 104 img/s | 11.28 ms | 10.0 ms | 12.72 ms |
| efficientnet-widese-b0 | 2 | 206 img/s | 11.41 ms | 10.65 ms | 12.72 ms |
| efficientnet-widese-b0 | 4 | 426 img/s | 11.15 ms | 10.23 ms | 11.03 ms |
| efficientnet-widese-b0 | 8 | 794 img/s | 11.9 ms | 12.68 ms | 14.17 ms |
| efficientnet-widese-b0 | 16 | 1536 img/s | 12.32 ms | 13.22 ms | 14.57 ms |
| efficientnet-widese-b0 | 32 | 2876 img/s | 14.12 ms | 14.45 ms | 16.23 ms |
| efficientnet-widese-b0 | 64 | 6183 img/s | 13.02 ms | 14.19 ms | 16.68 ms |
| efficientnet-widese-b0 | 128 | 9310 img/s | 20.06 ms | 15.24 ms | 17.84 ms |
| efficientnet-widese-b0 | 256 | 10193 img/s | 36.07 ms | 25.13 ms | 34.22 ms |
| efficientnet-widese-b4 | 1 | 53 img/s | 20.24 ms | 19.05 ms | 19.91 ms |
| efficientnet-widese-b4 | 2 | 109 img/s | 20.98 ms | 19.24 ms | 22.58 ms |
| efficientnet-widese-b4 | 4 | 213 img/s | 20.48 ms | 20.48 ms | 23.64 ms |
| efficientnet-widese-b4 | 8 | 425 img/s | 20.57 ms | 20.26 ms | 22.44 ms |
| efficientnet-widese-b4 | 16 | 800 img/s | 21.93 ms | 23.15 ms | 26.51 ms |
| efficientnet-widese-b4 | 32 | 1201 img/s | 28.51 ms | 26.89 ms | 28.13 ms |
| efficientnet-widese-b4 | 64 | 1322 img/s | 50.96 ms | 48.58 ms | 48.77 ms |
| efficientnet-widese-b4 | 128 | 1417 img/s | 96.45 ms | 90.17 ms | 90.43 ms |
| efficientnet-widese-b4 | 256 | 1439 img/s | 190.06 ms | 176.59 ms | 188.51 ms |
Inference performance: NVIDIA V100 (1x V100 16GB)
Our results were obtained by running the applicable efficientnet/inference/<AMP|FP32>/*.sh inference script in the PyTorch 21.03 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
FP32 Inference Latency
| Model | Batch Size | Throughput Avg | Latency Avg | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 83 img/s | 13.15 ms | 13.23 ms | 14.11 ms |
| efficientnet-b0 | 2 | 167 img/s | 13.17 ms | 13.46 ms | 14.39 ms |
| efficientnet-b0 | 4 | 332 img/s | 13.25 ms | 13.29 ms | 14.85 ms |
| efficientnet-b0 | 8 | 657 img/s | 13.42 ms | 13.86 ms | 15.77 ms |
| efficientnet-b0 | 16 | 1289 img/s | 13.78 ms | 15.02 ms | 16.99 ms |
| efficientnet-b0 | 32 | 2140 img/s | 16.46 ms | 18.92 ms | 22.2 ms |
| efficientnet-b0 | 64 | 2743 img/s | 25.14 ms | 23.44 ms | 23.79 ms |
| efficientnet-b0 | 128 | 2908 img/s | 48.03 ms | 43.98 ms | 45.36 ms |
| efficientnet-b0 | 256 | 2968 img/s | 94.86 ms | 85.62 ms | 91.01 ms |
| efficientnet-b4 | 1 | 45 img/s | 23.31 ms | 23.3 ms | 24.9 ms |
| efficientnet-b4 | 2 | 87 img/s | 24.07 ms | 23.81 ms | 25.14 ms |
| efficientnet-b4 | 4 | 160 img/s | 26.29 ms | 26.78 ms | 30.85 ms |
| efficientnet-b4 | 8 | 316 img/s | 26.65 ms | 26.44 ms | 28.61 ms |
| efficientnet-b4 | 16 | 341 img/s | 48.18 ms | 46.9 ms | 47.13 ms |
| efficientnet-b4 | 32 | 365 img/s | 89.07 ms | 87.83 ms | 88.02 ms |
| efficientnet-b4 | 64 | 374 img/s | 173.2 ms | 171.61 ms | 172.27 ms |
| efficientnet-b4 | 128 | 376 img/s | 346.32 ms | 339.74 ms | 340.37 ms |
| efficientnet-widese-b0 | 1 | 82 img/s | 13.37 ms | 12.95 ms | 13.89 ms |
| efficientnet-widese-b0 | 2 | 168 img/s | 13.11 ms | 12.45 ms | 13.94 ms |
| efficientnet-widese-b0 | 4 | 346 img/s | 12.73 ms | 12.22 ms | 12.95 ms |
| efficientnet-widese-b0 | 8 | 674 img/s | 13.07 ms | 12.75 ms | 14.93 ms |
| efficientnet-widese-b0 | 16 | 1235 img/s | 14.3 ms | 15.05 ms | 16.53 ms |
| efficientnet-widese-b0 | 32 | 2194 img/s | 15.99 ms | 17.37 ms | 19.01 ms |
| efficientnet-widese-b0 | 64 | 2747 img/s | 25.05 ms | 23.38 ms | 23.71 ms |
| efficientnet-widese-b0 | 128 | 2906 img/s | 48.05 ms | 44.0 ms | 44.59 ms |
| efficientnet-widese-b0 | 256 | 2962 img/s | 95.14 ms | 85.86 ms | 86.25 ms |
| efficientnet-widese-b4 | 1 | 43 img/s | 24.28 ms | 25.24 ms | 27.36 ms |
| efficientnet-widese-b4 | 2 | 87 img/s | 24.04 ms | 24.38 ms | 26.01 ms |
| efficientnet-widese-b4 | 4 | 169 img/s | 24.96 ms | 25.8 ms | 27.14 ms |
| efficientnet-widese-b4 | 8 | 307 img/s | 27.39 ms | 28.4 ms | 30.7 ms |
| efficientnet-widese-b4 | 16 | 342 img/s | 48.05 ms | 46.74 ms | 46.9 ms |
| efficientnet-widese-b4 | 32 | 363 img/s | 89.44 ms | 88.23 ms | 88.39 ms |
| efficientnet-widese-b4 | 64 | 373 img/s | 173.47 ms | 172.01 ms | 172.36 ms |
| efficientnet-widese-b4 | 128 | 376 img/s | 347.18 ms | 340.09 ms | 340.45 ms |
Mixed Precision Inference Latency
| Model | Batch Size | Throughput Avg | Latency Avg | Latency 95% | Latency 99% |
|---|---|---|---|---|---|
| efficientnet-b0 | 1 | 62 img/s | 17.19 ms | 18.01 ms | 18.63 ms |
| efficientnet-b0 | 2 | 119 img/s | 17.96 ms | 18.3 ms | 19.95 ms |
| efficientnet-b0 | 4 | 238 img/s | 17.9 ms | 17.8 ms | 19.13 ms |
| efficientnet-b0 | 8 | 495 img/s | 17.38 ms | 18.34 ms | 19.29 ms |
| efficientnet-b0 | 16 | 945 img/s | 18.23 ms | 19.42 ms | 21.58 ms |
| efficientnet-b0 | 32 | 1784 img/s | 19.29 ms | 20.71 ms | 22.51 ms |
| efficientnet-b0 | 64 | 3480 img/s | 20.34 ms | 22.22 ms | 24.62 ms |
| efficientnet-b0 | 128 | 5759 img/s | 26.11 ms | 22.61 ms | 24.06 ms |
| efficientnet-b0 | 256 | 6176 img/s | 49.36 ms | 41.18 ms | 43.5 ms |
| efficientnet-b4 | 1 | 34 img/s | 30.28 ms | 30.2 ms | 32.24 ms |
| efficientnet-b4 | 2 | 69 img/s | 30.12 ms | 30.02 ms | 31.92 ms |
| efficientnet-b4 | 4 | 129 img/s | 32.08 ms | 33.29 ms | 34.74 ms |
| efficientnet-b4 | 8 | 242 img/s | 34.43 ms | 37.34 ms | 41.08 ms |
| efficientnet-b4 | 16 | 488 img/s | 34.12 ms | 36.13 ms | 39.39 ms |
| efficientnet-b4 | 32 | 738 img/s | 44.67 ms | 44.85 ms | 47.86 ms |
| efficientnet-b4 | 64 | 809 img/s | 80.93 ms | 79.19 ms | 79.42 ms |
| efficientnet-b4 | 128 | 843 img/s | 156.42 ms | 152.17 ms | 152.76 ms |
| efficientnet-b4 | 256 | 847 img/s | 311.03 ms | 301.44 ms | 302.48 ms |
| efficientnet-widese-b0 | 1 | 64 img/s | 16.71 ms | 17.59 ms | 19.23 ms |
| efficientnet-widese-b0 | 2 | 129 img/s | 16.63 ms | 16.1 ms | 17.34 ms |
| efficientnet-widese-b0 | 4 | 238 img/s | 17.92 ms | 17.52 ms | 18.82 ms |
| efficientnet-widese-b0 | 8 | 445 img/s | 19.24 ms | 19.53 ms | 20.4 ms |
| efficientnet-widese-b0 | 16 | 936 img/s | 18.64 ms | 19.55 ms | 21.1 ms |
| efficientnet-widese-b0 | 32 | 1818 img/s | 18.97 ms | 20.62 ms | 23.06 ms |
| efficientnet-widese-b0 | 64 | 3572 img/s | 19.81 ms | 21.14 ms | 23.29 ms |
| efficientnet-widese-b0 | 128 | 5748 img/s | 26.18 ms | 23.72 ms | 26.1 ms |
| efficientnet-widese-b0 | 256 | 6187 img/s | 49.11 ms | 41.11 ms | 41.59 ms |
| efficientnet-widese-b4 | 1 | 32 img/s | 32.1 ms | 31.6 ms | 34.69 ms |
| efficientnet-widese-b4 | 2 | 68 img/s | 30.4 ms | 30.9 ms | 32.67 ms |
| efficientnet-widese-b4 | 4 | 123 img/s | 33.81 ms | 39.0 ms | 40.76 ms |
| efficientnet-widese-b4 | 8 | 257 img/s | 32.34 ms | 33.39 ms | 34.93 ms |
| efficientnet-widese-b4 | 16 | 497 img/s | 33.51 ms | 34.92 ms | 37.24 ms |
| efficientnet-widese-b4 | 32 | 739 img/s | 44.63 ms | 43.62 ms | 46.39 ms |
| efficientnet-widese-b4 | 64 | 808 img/s | 81.08 ms | 79.43 ms | 79.59 ms |
| efficientnet-widese-b4 | 128 | 840 img/s | 157.11 ms | 152.87 ms | 153.26 ms |
| efficientnet-widese-b4 | 256 | 846 img/s | 310.73 ms | 301.68 ms | 302.9 ms |
Quantization results
QAT Training performance: NVIDIA DGX-1 (8x V100 32GB)
| Model | GPUs | Calibration | QAT model | FP32 | QAT ratio |
|---|---|---|---|---|---|
| efficientnet-quant-b0 | 8 | 14.71 img/s | 2644.62 img/s | 3798 img/s | 0.696 x |
| efficientnet-quant-b4 | 8 | 1.85 img/s | 310.41 img/s | 666 img/s | 0.466 x |
Quant Inference accuracy
The best checkpoints generated during training were used as a base for the QAT.
| Model | QAT Epochs | QAT Top1 | Gap between FP32 Top1 and QAT Top1 |
|---|---|---|---|
| efficientnet-quant-b0 | 10 | 77.12 | 0.51 |
| efficientnet-quant-b4 | 2 | 82.54 | 0.44 |