BERT is a method of pre-training language representations which obtains state-of-the-art results on a wide array of NLP tasks.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. This model is based on the BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper. NVIDIA's BERT is an optimized version of Google's official implementation, leveraging mixed precision arithmetic and Tensor Cores on V100 GPUs for faster training times while maintaining target accuracy.
Other publicly available implementations of BERT include: NVIDIA PyTorch Hugging Face codertimo gluon-nlp Google's official implementation
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 4x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
BERT's model architecture is a multi-layer bidirectional transformer encoder. Based on the model size, we have the following two default configurations of BERT:
| Model | Hidden layers | Hidden unit size | Attention heads | Feedforward filter size | Max sequence length | Parameters |
|---|---|---|---|---|---|---|
| BERTBASE | 12 encoder | 768 | 12 | 4 x 768 | 512 | 110M |
| BERTLARGE | 24 encoder | 1024 | 16 | 4 x 1024 | 512 | 330M |
BERT training consists of two steps, pre-training the language model in an unsupervised fashion on vast amounts of unannotated datasets, and then using this pre-trained model for fine-tuning for various NLP tasks, such as question and answer, sentence classification, or sentiment analysis. Fine-tuning typically adds an extra layer or two for the specific task and further trains the model using a task-specific annotated dataset, starting from the pre-trained backbone weights. The end-to-end process is depicted in the following image:
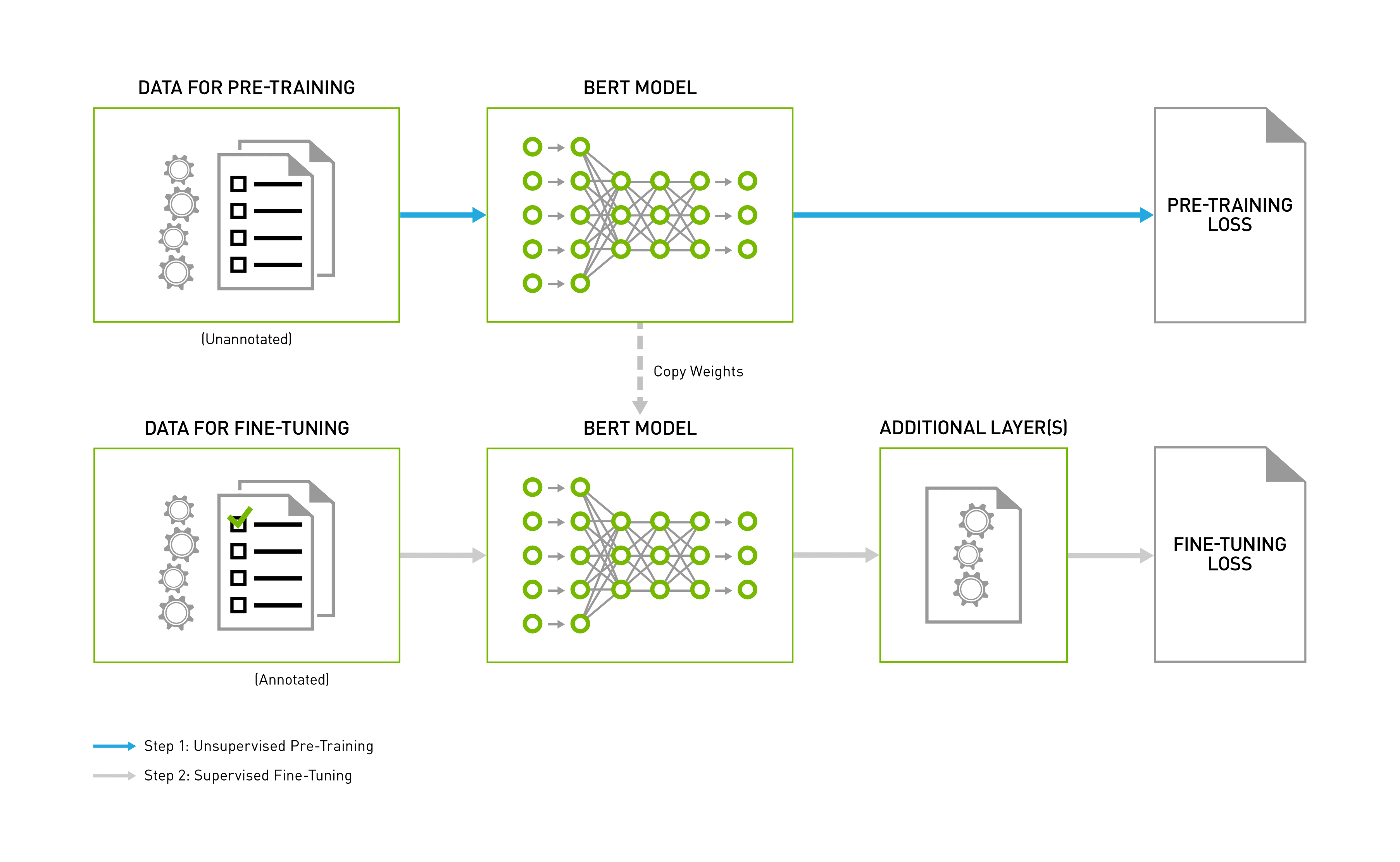
Figure 1: BERT Pipeline
Default configuration
This repository contains scripts to interactively launch data download, training, benchmarking, and inference routines in a Docker container for fine tuning Question Answering. The major differences between the official implementation of the paper and our version of BERT are as follows:
- Mixed precision support with TensorFlow Automatic Mixed Precision (TF-AMP), which enables mixed precision training without any changes to the code-base by performing automatic graph rewrites and loss scaling controlled by an environmental variable.
- Scripts to download dataset and pretrained checkpoints for:
- Pre-training - Wikipedia, BookCorpus
- Fine tuning - SQuAD (Stanford Question Answering Dataset)
- Pretrained weights from Google
- Custom fused CUDA kernels for faster computations
- Multi-GPU/Multi-node support using Horovod
The following performance optimizations were implemented in this model:
- XLA support (experimental).
These techniques and optimizations improve model performance and reduce training time, allowing you to perform various NLP tasks with no additional effort.
Feature support matrix
The following features are supported by this model.
| Feature | BERT |
|---|---|
| Horovod Multi-GPU | Yes |
| Horovod Multi-node | Yes |
| Automatic mixed precision (AMP) | Yes |
| XLA | Yes |
| LAMB | Yes |
Features
Multi-GPU training with Horovod Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, see example sources in this repository or see the TensorFlow tutorial.
XLA support
XLA is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes. The results are improvements in speed and memory usage: most internal benchmarks run ~1.1-1.5x faster after XLA is enabled.
Multi-node Training
Supported on a Pyxis/Enroot Slurm cluster.
LAMB
LAMB stands for Layerwise Adaptive Moments based optimizer, is a large batch optimization technique that helps accelerate training of deep neural networks using large minibatches. It allows using a global batch size of 65536 and 32768 on sequence lengths 128 and 512 respectively, compared to a batch size of 256 for Adam. The optimized implementation accumulates 1024 gradient batches in phase 1 and 4096 steps in phase 2 before updating weights once. This results in 27% training speedup on a single DGX2 node. On multi-node systems, LAMB allows scaling up to 1024 GPUs resulting in training speedups of up to 17x in comparison to Adam. Adam has limitations on the learning rate that can be used since it is applied globally on all parameters whereas LAMB follows a layerwise learning rate strategy.
NVLAMB adds necessary tweaks to LAMB version 1, to ensure correct convergence. A guide to implementating the LAMB optimizer can be found in our article on Medium.com. The algorithm is as follows:

Mixed precision training
Mixed precision is the combined use of different numerical precision in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full mixed precision methodology in your existing TensorFlow model code. AMP enables mixed precision training on Volta, Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed Precision Training of Deep Neural Networks blog.
- How to access and enable AMP for TensorFlow, see Using TF-AMP from the TensorFlow User Guide.
Enabling mixed precision
This implementation exploits the TensorFlow Automatic Mixed Precision feature. To enable AMP, you simply need to supply the --use_fp16 flag to the run_pretraining.py or run_squad.py script. For reference, enabling AMP required us to apply the following changes to the code:
-
Set the Keras mixed precision policy:
if FLAGS.use_fp16: policy = tf.keras.mixed_precision.experimental.Policy("mixed_float16") tf.keras.mixed_precision.experimental.set_policy(policy) -
Use the loss scaling wrapper on the optimizer:
if FLAGS.use_fp16: squad_model.optimizer = tf.keras.mixed_precision.LossScaleOptimizer(squad_model.optimizer, dynamic=True) -
Use scaled loss to calculate the gradients:
if use_float16: scaled_loss = optimizer.get_scaled_loss(loss) scaled_grads = tape.gradient(scaled_loss, training_vars) grads = optimizer.get_unscaled_gradients(scaled_grads)
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Fine-tuning Training an already pretrained model further using a task specific dataset for subject-specific refinements, by adding task-specific layers on top if required.
Language model Assigns a probability distribution over a sequence of words. Given a sequence of words, it assigns a probability to the whole sequence.
Pre-training Training a model on vast amounts of data on the same (or different) task to build general understandings.
Transformer The paper Attention Is All You Need introduces a novel architecture called Transformer that uses an attention mechanism and transforms one sequence into another.