BERT is a method of pre-training language representations which obtains state-of-the-art results on a wide array of NLP tasks.
Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
Training performance benchmark
Training performance benchmarks for pre-training can be obtained by running scripts/run_pretraining.sh, and for fine-tuning can be obtained by running scripts/run_squad.sh or scripts/run_glue.sh for SQuAD or GLUE, respectively. The required parameters can be passed through the command-line as described in Training process.
As an example, to benchmark the training performance on a specific batch size for SQuAD, run:
bash scripts/run_squad.sh <pre-trained checkpoint path> <epochs> <batch size> <learning rate> <fp16|fp32> <num_gpus> <seed> <path to SQuAD dataset> <path to vocab set> <results directory> train <BERT config path] <max steps>
An example call used to generate throughput numbers:
bash scripts/run_squad.sh /workspace/bert/bert_large_uncased.pt 2.0 4 3e-5 fp16 8 42 /workspace/bert/squad_data /workspace/bert/scripts/vocab/vocab /results/SQuAD train /workspace/bert/bert_config.json -1
Inference performance benchmark
Inference performance benchmarks for both fine-tuning can be obtained by running scripts/run_squad.sh and scripts/run_glue.sh respectively. The required parameters can be passed through the command-line as described in Inference process.
As an example, to benchmark the inference performance on a specific batch size for SQuAD, run:
bash scripts/run_squad.sh <pre-trained checkpoint path> <epochs> <batch size> <learning rate> <fp16|fp32> <num_gpus> <seed> <path to SQuAD dataset> <path to vocab set> <results directory> eval <BERT config path> <max steps>
An example call used to generate throughput numbers:
bash scripts/run_squad.sh /workspace/bert/bert_large_uncased.pt 2.0 4 3e-5 fp16 8 42 /workspace/bert/squad_data /workspace/bert/scripts/vocab/vocab /results/SQuAD eval /workspace/bert/bert_config.json -1
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Our results were obtained by running the scripts/run_squad.sh and scripts/run_pretraining.sh training scripts in the pytorch:21.11-py3 NGC container unless otherwise specified.
Pre-training loss results: NVIDIA DGX A100 (8x A100 80GB)
| DGX System | GPUs / Node | Batch size / GPU (Phase 1 and Phase 2) | Accumulated Batch size / GPU (Phase 1 and Phase 2) | Accumulation steps (Phase 1 and Phase 2) | Final Loss - TF32 | Final Loss - mixed precision | Time to train(hours) - TF32 | Time to train(hours) - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|---|---|---|
| 32 x DGX A100 80GB | 8 | 256 and 32 | 256 and 128 | 1 and 4 | --- | 1.2437 | --- | 1.2 | 1.9 |
| 32 x DGX A100 80GB | 8 | 128 and 16 | 256 and 128 | 2 and 8 | 1.2465 | --- | 2.4 | --- | --- |
Pre-training loss curves
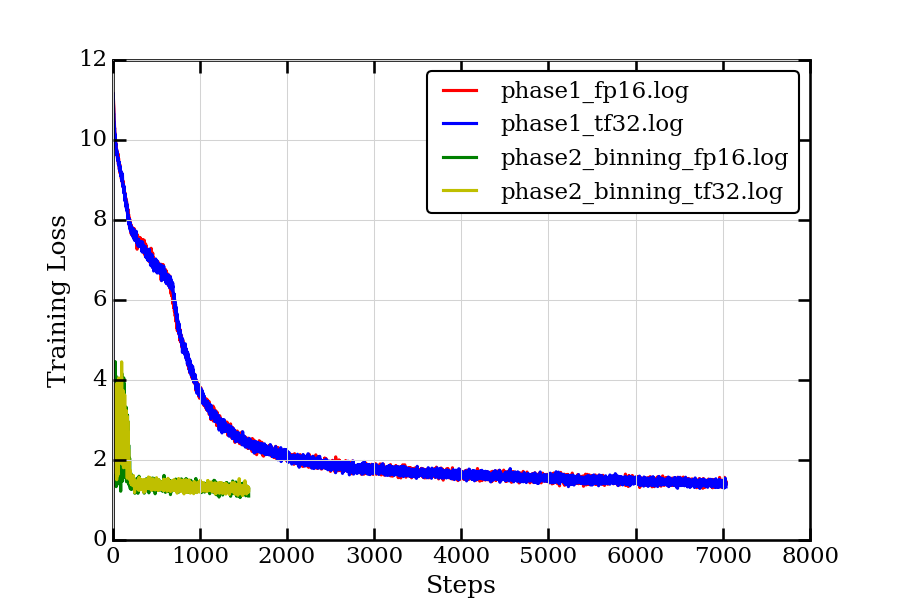
Fine-tuning accuracy results: NVIDIA DGX A100 (8x A100 80GB)
- SQuAD
| GPUs | Batch size / GPU (TF32 and FP16) | Accuracy - TF32(% F1) | Accuracy - mixed precision(% F1) | Time to train(hours) - TF32 | Time to train(hours) - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 32 | 90.93 | 90.96 | 0.102 | 0.0574 | 1.78 |
- MRPC
| GPUs | Batch size / GPU (TF32 and FP16) | Accuracy - TF32(%) | Accuracy - mixed precision(%) | Time to train(seconds) - TF32 | Time to train(seconds) - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 16 | 87.25 | 88.24 | 17.26 | 7.31 | 2.36 |
- SST-2
| GPUs | Batch size / GPU (TF32 and FP16) | Accuracy - TF32(%) | Accuracy - mixed precision(%) | Time to train(seconds) - TF32 | Time to train(seconds) - mixed precision | Time to train speedup (TF32 to mixed precision) |
|---|---|---|---|---|---|---|
| 8 | 128 | 91.97 | 92.78 | 119.28 | 62.59 | 1.91 |
Training stability test
Pre-training stability test
| Accuracy Metric | Seed 0 | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|
| Final Loss | 1.260 | 1.265 | 1.304 | 1.256 | 1.242 | 1.265 | 0.023 |
Fine-tuning stability test
- SQuAD
Training stability with 8 GPUs, FP16 computations, batch size of 4:
| Accuracy Metric | Seed 0 | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Seed 5 | Seed 6 | Seed 7 | Seed 8 | Seed 9 | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact Match % | 83.64 | 84.05 | 84.51 | 83.69 | 83.87 | 83.94 | 84.27 | 83.97 | 83.75 | 83.92 | 83.96 | 0.266 |
| f1 % | 90.60 | 90.65 | 90.96 | 90.44 | 90.58 | 90.78 | 90.81 | 90.82 | 90.51 | 90.68 | 90.68 | 0.160 |
- MRPC
Training stability with 8 A100 GPUs, FP16 computations, batch size of 16 per GPU:
| Accuracy Metric | Seed 0 | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Seed 5 | Seed 6 | Seed 7 | Seed 8 | Seed 9 | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact Match % | 85.78 | 85.54 | 84.56 | 86.27 | 84.07 | 86.76 | 87.01 | 85.29 | 88.24 | 86.52 | 86.00 | 1.225 |
Note: Since MRPC is a very small dataset where overfitting can often occur, the resulting validation accuracy can often have high variance. By repeating the above experiments for 100 seeds, the max accuracy is 88.73, and the average accuracy is 82.56 with a standard deviation of 6.01.
- SST-2
Training stability with 8 A100 GPUs, FP16 computations, batch size of 128 per GPU:
| Accuracy Metric | Seed 0 | Seed 1 | Seed 2 | Seed 3 | Seed 4 | Seed 5 | Seed 6 | Seed 7 | Seed 8 | Seed 9 | Mean | Standard Deviation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact Match % | 91.86 | 91.28 | 91.86 | 91.74 | 91.28 | 91.86 | 91.40 | 91.97 | 91.40 | 92.78 | 91.74 | 0.449 |
Training performance results
Training performance: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the scripts run_pretraining.sh training script in the pytorch:21.11-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs. Performance numbers (in items/images per second) were averaged over a few training iterations.
Pre-training NVIDIA DGX A100 (8x A100 80GB)
| GPUs | Batch size / GPU (TF32 and FP16) | Accumulated Batch size / GPU (TF32 and FP16) | Accumulation steps (TF32 and FP16) | Sequence length | Throughput - TF32(sequences/sec) | Throughput - mixed precision(sequences/sec) | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 128 and 256 | 8192 and 8192 | 64 and 32 | 128 | 317 | 580 | 1.83 | 1.00 | 1.00 |
| 8 | 128 and 256 | 8192 and 8192 | 64 and 32 | 128 | 2505 | 4591 | 1.83 | 7.90 | 7.91 |
| 1 | 16 and 32 | 4096 and 4096 | 256 and 128 | 512 | 110 | 210 | 1.90 | 1.00 | 1.00 |
| 8 | 16 and 32 | 4096 and 4096 | 256 and 128 | 512 | 860 | 1657 | 1.92 | 7.81 | 7.89 |
Pre-training NVIDIA DGX A100 (8x A100 80GB) Multi-node Scaling
| Nodes | GPUs / node | Batch size / GPU (TF32 and FP16) | Accumulated Batch size / GPU (TF32 and FP16) | Accumulation steps (TF32 and FP16) | Sequence length | Mixed Precision Throughput | Mixed Precision Strong Scaling | TF32 Throughput | TF32 Strong Scaling | Speedup (Mixed Precision to TF32) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 8 | 126 and 256 | 8192 and 8192 | 64 and 32 | 128 | 4553 | 1 | 2486 | 1 | 1.83 |
| 2 | 8 | 126 and 256 | 4096 and 4096 | 32 and 16 | 128 | 9191 | 2.02 | 4979 | 2.00 | 1.85 |
| 4 | 8 | 126 and 256 | 2048 and 2048 | 16 and 18 | 128 | 18119 | 3.98 | 9859 | 3.97 | 1.84 |
| 8 | 8 | 126 and 256 | 1024 and 1024 | 8 and 4 | 128 | 35774 | 7.86 | 19815 | 7.97 | 1.81 |
| 16 | 8 | 126 and 256 | 512 and 512 | 4 and 2 | 128 | 70555 | 15.50 | 38866 | 15.63 | 1.82 |
| 32 | 8 | 126 and 256 | 256 and 256 | 2 and 1 | 128 | 138294 | 30.37 | 75706 | 30.45 | 1.83 |
| 1 | 8 | 16 and 32 | 4096 and 4096 | 256 and 128 | 512 | 1648 | 1 | 854 | 1 | 1.93 |
| 2 | 8 | 16 and 32 | 2048 and 2048 | 128 and 64 | 512 | 3291 | 2.00 | 1684 | 1.97 | 1.95 |
| 4 | 8 | 16 and 32 | 1024 and 1024 | 64 and 32 | 512 | 6464 | 3.92 | 3293 | 3.86 | 1.96 |
| 8 | 8 | 16 and 32 | 512 and 512 | 32 and 16 | 512 | 13005 | 7.89 | 6515 | 7.63 | 2.00 |
| 16 | 8 | 16 and 32 | 256 and 256 | 16 and 8 | 512 | 25570 | 15.51 | 12131 | 14.21 | 2.11 |
| 32 | 8 | 16 and 32 | 128 and 128 | 8 and 4 | 512 | 49663 | 30.13 | 21298 | 24.95 | 2.33 |
Fine-tuning NVIDIA DGX A100 (8x A100 80GB)
- SQuAD
| GPUs | Batch size / GPU (TF32 and FP16) | Throughput - TF32(sequences/sec) | Throughput - mixed precision(sequences/sec) | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 32 and 32 | 61.5 | 110.5 | 1.79 | 1.00 | 1.00 |
| 8 | 32 and 32 | 469.8 | 846.7 | 1.80 | 7.63 | 7.66 |
Training performance: NVIDIA DGX-1 (8x V100 32G)
Our results were obtained by running the scripts/run_pretraining.sh and scripts/run_squad.sh training scripts in the pytorch:21.11-py3 NGC container on NVIDIA DGX-1 with (8x V100 32G) GPUs. Performance numbers (in sequences per second) were averaged over a few training iterations.
Pre-training NVIDIA DGX-1 With 32G
| GPUs | Batch size / GPU (FP32 and FP16) | Accumulation steps (FP32 and FP16) | Sequence length | Throughput - FP32(sequences/sec) | Throughput - mixed precision(sequences/sec) | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|---|---|
| 1 | 4096 and 4096 | 128 and 64 | 128 | 50 | 224 | 4.48 | 1.00 | 1.00 |
| 8 | 4096 and 4096 | 128 and 64 | 128 | 387 | 1746 | 4.51 | 7.79 | 7.79 |
| 1 | 2048 and 2048 | 512 and 256 | 512 | 19 | 75 | 3.94 | 1.00 | 1.00 |
| 8 | 2048 and 2048 | 512 and 256 | 512 | 149.6 | 586 | 3.92 | 7.87 | 7.81 |
Fine-tuning NVIDIA DGX-1 With 32G
- SQuAD
| GPUs | Batch size / GPU (FP32 and FP16) | Throughput - FP32(sequences/sec) | Throughput - mixed precision(sequences/sec) | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|---|---|---|---|---|---|---|
| 1 | 8 and 16 | 12 | 52 | 4.33 | 1.00 | 1.00 |
| 8 | 8 and 16 | 85.5 | 382 | 4.47 | 7.12 | 7.34 |
To achieve these same results, follow the steps in the Quick Start Guide.
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 80GB)
Our results were obtained by running scripts/run_squad.sh in the pytorch:21.11-py3 NGC container on NVIDIA DGX A100 with (1x A100 80G) GPUs.
Fine-tuning inference on NVIDIA DGX A100 (1x A100 80GB)
- SQuAD
| GPUs | Batch Size (TF32/FP16) | Sequence Length | Throughput - TF32(sequences/sec) | Throughput - Mixed Precision(sequences/sec) |
|---|---|---|---|---|
| 1 | 32/32 | 384 | 216 | 312 |
To achieve these same results, follow the steps in the Quick Start Guide.
The inference performance metrics used were sequences/second.