BERT is a method of pre-training language representations which obtains state-of-the-art results on a wide array of NLP tasks.
This resource is using open-source code maintained in github (see the quick-start-guide section) and available for download from NGC
Bidirectional Encoder Representations from Transformers (BERT) is a new method of pre-training language representations that obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. This model is based on the BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper.
This repository contains scripts to interactively launch data download, training, benchmarking, and inference routines in a Docker container for pre-training and fine-tuning tasks such as question answering. The major differences between the original implementation of the paper and this version of BERT are as follows:
- Scripts to download the Wikipedia dataset
- Scripts to preprocess downloaded data into inputs and targets for pre-training in a modular fashion
- LAMB optimizer to support training with larger batches
- Adam optimizer for fine-tuning tasks
- Automatic mixed precision (AMP) training support
Other publicly available implementations of BERT include:
This model trains with mixed precision Tensor Cores on NVIDIA Ampere and provides a push-button solution to pre-training on a corpus of choice. As a result, researchers can get results 4x faster than training without Tensor Cores. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
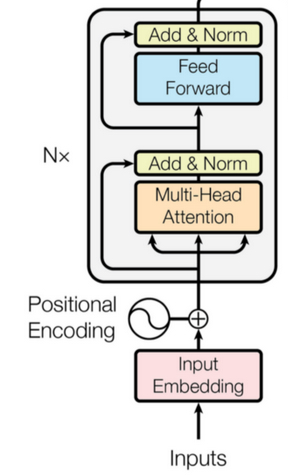
The BERT model uses the same architecture as the encoder of the Transformer. Input sequences are projected into an embedding space before being fed into the encoder structure. Additionally, positional and segment encodings are added to the embeddings to preserve positional information. The encoder structure is simply a stack of Transformer blocks, which consist of a multi-head attention layer followed by successive stages of feed-forward networks and layer normalization. The multi-head attention layer accomplishes self-attention on multiple input representations.
An illustration of the architecture taken from the Transformer paper is shown below.
Default configuration
The architecture of the BERT model is almost identical to the Transformer model that was first introduced in the Attention Is All You Need paper. The main innovation of BERT lies in the pre-training step, where the model is trained on two unsupervised prediction tasks using a large text corpus. Training on these unsupervised tasks produces a generic language model, which can then be quickly fine-tuned to achieve state-of-the-art performance on language processing tasks such as question answering.
The BERT paper reports the results for two configurations of BERT, each corresponding to a unique model size. This implementation provides the same default configurations, which are described in the table below.
| Model | Hidden layers | Hidden unit size | Attention heads | Feedforward filter size | Max sequence length | Parameters |
|---|---|---|---|---|---|---|
| BERTBASE | 12 encoder | 768 | 12 | 4 x 768 | 512 | 110M |
| BERTLARGE | 24 encoder | 1024 | 16 | 4 x 1024 | 512 | 330M |
Feature support matrix
The following features are supported by this model.
| Feature | BERT |
|---|---|
| Paddle AMP | Yes |
| Paddle Fleet | Yes |
| LAMB | Yes |
| LDDL | Yes |
| Multi-node | Yes |
Features
Fleet is a unified API for distributed training of PaddlePaddle.
LAMB stands for Layerwise Adaptive Moments based optimizer, which is a large batch optimization technique that helps accelerate the training of deep neural networks using large minibatches. It allows using a global batch size of 65536 and 32768 on sequence lengths 128 and 512, respectively, compared to a batch size of 256 for Adam. The optimized implementation accumulates 1024 gradient batches in phase 1 and 4096 steps in phase 2 before updating weights once. This results in a 15% training speedup. On multi-node systems, LAMB allows scaling up to 1024 GPUs resulting in training speedups of up to 72x in comparison to Adam. Adam has limitations on the learning rate that can be used since it is applied globally on all parameters, whereas LAMB follows a layerwise learning rate strategy.
LDDL is a library that enables scalable data preprocessing and loading. LDDL is used by this PaddlePaddle BERT example.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in NVIDIA Volta, and following with both the NVIDIA Turing and NVIDIA Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision in PaddlePaddle, refer to the Mixed Precision Training paper and Automatic Mixed Precision Training documentation.
- Techniques used for mixed precision training, refer to the Mixed-Precision Training of Deep Neural Networks blog.
Enabling mixed precision
Mixed precision is enabled in Paddle by using the Automatic Mixed Precision (AMP) while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a loss scaling step must be included when applying gradients. In PaddlePaddle, loss scaling can be easily applied by passing in arguments to GradScaler(). The scaling value to be used can be dynamic or fixed.
For an in-depth walkthrough on AMP, check out sample usage here. Paddle AMP is a PaddlePaddle built-in module that provides functions to construct AMP workflow. The details can be found in Automatic Mixed Precision (AMP), which requires minimal network code changes to leverage Tensor Cores performance.
Code example to enable mixed precision for static graph:
-
Use
paddle.static.amp.decorateto wrap optimizerimport paddle.static.amp as amp mp_optimizer = amp.decorate(optimizer=optimizer, init_loss_scaling=8.0) -
Minimize
loss, and getscaled_loss, which is useful when you need customized loss.ops, param_grads = mp_optimizer.minimize(loss) scaled_loss = mp_optimizer.get_scaled_loss() -
For distributed training, it is recommended to use Fleet to enable amp, which is a unified API for distributed training of PaddlePaddle. For more information, refer to Fleet
import paddle.distributed.fleet as fleet strategy = fleet.DistributedStrategy() strategy.amp = True # by default this is false optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math, also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models, which require a high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Glossary
Fine-tuning
Training an already pre-trained model further using a task-specific dataset for subject-specific refinements by adding task-specific layers on top if required.
Language Model
Assigns a probability distribution over a sequence of words. Given a sequence of words, it assigns a probability to the whole sequence.
Pre-training
Training a model on vast amounts of data on the same (or different) task to build general understandings.
Transformer
The paper Attention Is All You Need introduces a novel architecture called Transformer that uses an attention mechanism and transforms one sequence into another.
Phase 1
Pre-training on samples of sequence length 128 and 20 masked predictions per sequence.
Phase 2
Pre-training on samples of sequence length 512 and 80 masked predictions per sequence.