The Domain Specific - NeMo Automatic Speech Recognition (ASR) Application facilitates training, evaluation and performance comparison of ASR models. This NeMo application enables you to train or fine-tune pre-trained ASR models with your own data.
Domain Specific – NeMo ASR Application
The Domain Specific - NeMo Automatic Speech Recognition (ASR) Application facilitates training, evaluation and performance comparison of ASR models. This NeMo application enables you to train or fine-tune pre-trained ASR models with your own data. Through this application, we empower you to create your own ASR models built for your domain specific data. Developers have complete control over their data unlike when using a “black box” ASR tool available in the cloud, giving you the ability to create better performing ASR models for your use case.
The Domain Specific - NeMo ASR Application is a packaged easy to use end-to-end ASR system that facilitates:
- Dataset preparation and exploration
- Acoustic Model training and fine tuning with your own data
- Transcription (speech to text) with the models created
- Easy understanding of performance progression of models
- Model preparation to export for deployment
We use the NVIDIA Neural Modules (NeMo) as the underlying ASR engine. NeMo is a toolkit for building Conversational AI applications. Through modular Deep Neural Networks (DNN) development, NeMo enables fast experimentation by connecting modules, mixing and matching components. Neural Modules are conceptual blocks of neural networks that take typed inputs and produce typed outputs, these typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition (ASR), natural language processing (NLP) and text synthesis (TTS).
To learn more
Please review the following resources, you can also use these to post your questions.
- NVIDIA Developer Blog - How to Build Domain Specific Automatic Speech Recognition Models on GPUs
- GTC Talk - GTC 2020: Do-it-Yourself Automatic Speech Recognition with NVIDIA Technologies
Table of Contents
Installation and Getting Started
Getting started with the application is very simple.
Running from NGC container
This image contains the complete Domain Specific NeMo ASR application (including NeMo, notebooks, tools and scripts).
1. Download the container from NGC
docker pull nvcr.io/nvidia/nemo_asr_app_img:20.07
2. Run the application
To run the application, you need to mount the directory where the training datasets live and the results will be saved to. In the run command below, we use the /data/asr directory as the $DATA_DIR.
export DATA_DIR="/data/asr" \
docker run --gpus all -it --rm --name run_nemo_asr_app \
--ipc=host \
--env DATA_DIR=$DATA_DIR \
-v $DATA_DIR:$DATA_DIR \
-p 8888:8888 nvcr.io/nvidia/nemo_asr_app_img:20.07
Note: Depending on your docker version you may have to use ‘docker run --runtime=nvidia’ or remove ‘--gpus all’
Domain ASR Application
In our application, we provide a complete end-to-end workflow to enable domain adaptation of ASR models using your own data. This is done through the following steps:
- Preparations: Download pre-trained models, download and prepare datasets, project creation for tracking
- Train (fine-tune) Acoustic Model
- Inference with fine-tuned models
- Performance (Word Error Rate) comparison
Code Structure
The application is divided into the following sturcutre:
- example_audios: Example audios for demos.
- models: Folder with fine-tuned models.
- tools: Scripts and tools that enable the system's functionality.
- run_app.sh and Dockerfile: Scripts to build and run the application.
- Notebooks (.ipynb): Example notebooks to build ASR models with NeMo.
Example Use Cases
In our application we cover the following use cases:
English to Spanish Cross Language Finetuning:
In this use case, we finetune an English acoustic model with Spanish data to create a SOTA Spanish ASR model. Specifically, we fine-tune a pre-trained English ASR model trained on five English datasets with a Spanish open source dataset from Common Voice. Common Voice is a multi-language dataset that anyone can use to train speech-enabled applications.
Wall Street Journal Finetuning:
For this second use case, we perform transfer learning or domain adaptation from old fiction books to modern business news. We use a pre-trained model, QuartzeNet 15x5, found in NGC. This model is pre-trained on the opensource English datasets LibriSpeech and English - Mozilla Common Voice. We fine tune this model with The Wall Street Journal (WSJ) news datasets, WSJ CSR-1 and WSJ CSR-2. To run this use case you need to bring your own dataset or download and prepare the WSJ dataset used in our example WSJ CSR-1 and WSJ CSR-2. Note, you need a license to download the WSJ dataset.
Project Tracking of Data, Models and Configurations
To simplify and enable reproducibility of the ASR workflow, our application allows you to create a project which enables the tracking of datasets, models and configurations. Everything related to a project is saved to disk in a manifest that can be accessed through its project_id. At the start of the project, the manifest is pre-populated with the baseline pre-trained model.
Additionally, we enable experiment tracking with Weights and Bias which provides you with in depth hyperparameter tracking and collaboration of projects and experiments.
Automatic Speech Recognition Pipeline
The NeMo ASR acoustic model used in this application is QuartzNet. The QuartzNet model is based on Jasper and can achieve the same performance but with less parameters (from about 333M to about 19M). This model consists of separable convolutions and larger filters, often denoted by QuartzNet_[BxR], where B is the number of blocks, and R - the number of convolutional sub-blocks within a block. Each sub-block contains a 1-D separable convolution, batch normalization, ReLU, and dropout. To learn more about NeMo’s ASR models refer to this tutorial.
Jasper and QuartzNet are CTC-based end-to-end models, which can predict a transcript directly from an audio input, without additional alignment information.
To learn more about the NeMo ASR engine training and evaluation workflows, refer to the quartznet.py, jasper_train.py and jasper_eval.py scripts inside the tools folder.
ASR-CTC pipeline
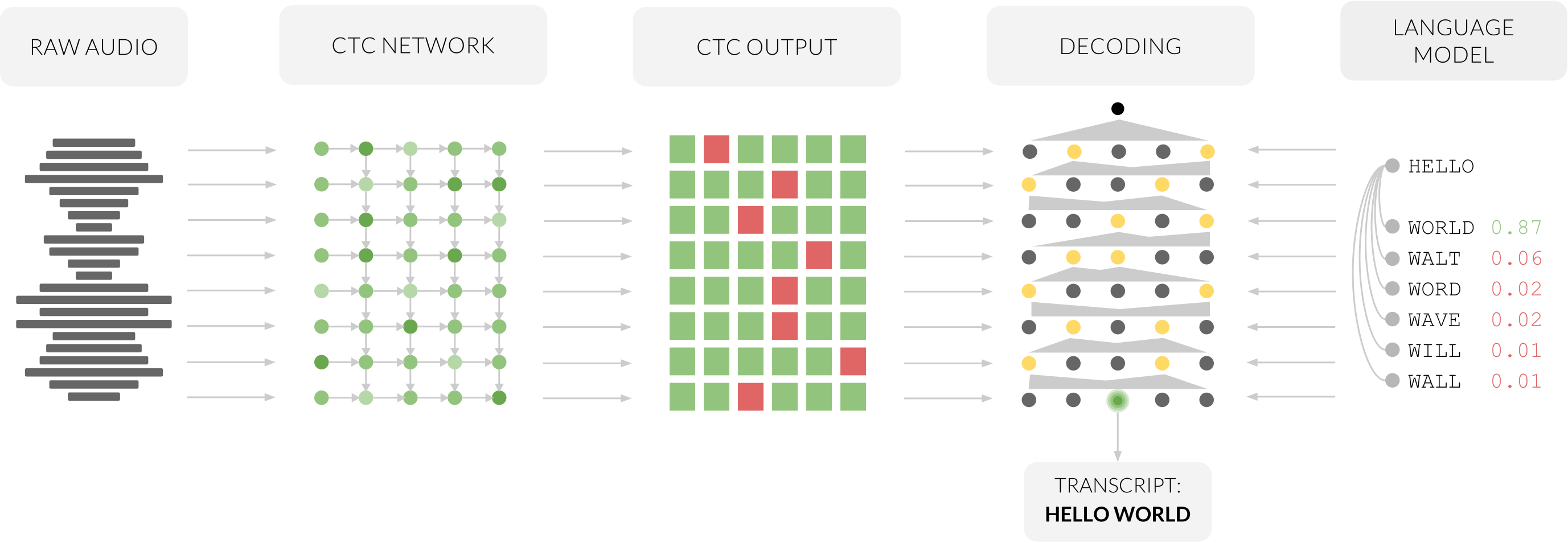
Image Source: CTC Networks and Language Models: Prefix Beam Search Explained
The typical ASR-CTC pipeline is shown in the Figure above. Here, the CTC network creates a probability CTC matrix, from the audio input, where columns represent a timestep and rows correspond to a letter in our alphabet, note the probabilities of each column (across all letters) sum to 1. For prediction using max decoding or greedy decoding, the letter with the highest probability at each timestep is chosen, in other words a temporal softmax output layer is used. Next, the repeated characters are removed or collapsed, and blank tokens are discarded. Additionally, a language model can be used to solve ambiguities in the transcription or softmax output, with the help of linguistic knowledge provided by a prefix beam search. To learn more refer to this link.
The CTC-ASR training pipeline followed by NeMo is shown in the following figure:

Image Source: NVIDIA Neural Modules: NeMo
This includes:
- Audio preprocessing (feature extraction): signal normalization, windowing, (log) spectrogram (or mel scale spectrogram, or MFCC)
- Neural acoustic model (which predicts a probability distribution P_t(c) over vocabulary characters c per each time step t given input features per each timestep)
- CTC loss function
Getting Help & Support
If you have any questions or need help, please email npn-ds@nvidia.com